
La recherche en intelligence artificielle et Machine Learning est largement dominée par une poignée d’ensembles de données (datasets), élaborés par l’élite des institutions occidentales. Une étude menée par l’Université de Californie et Google Research pointe du doigt cet inquiétant phénomène et ses conséquences néfastes….
La recherche en intelligence artificielle se développe à vive allure. Malheureusement, elle est largement dominée par un petit nombre d’ensembles de données benchmark Machine Learning. C’est ce que révèle une étude menée par l’Université de Californie et Google Research.
Ces » datasets » proviennent principalement d’institutions occidentales, et bien souvent d’organisations gouvernementales. Or, selon les chercheurs à l’origine de cette étude, cette tendance pose un certain nombre de problèmes éthiques, techniques et même politiques.
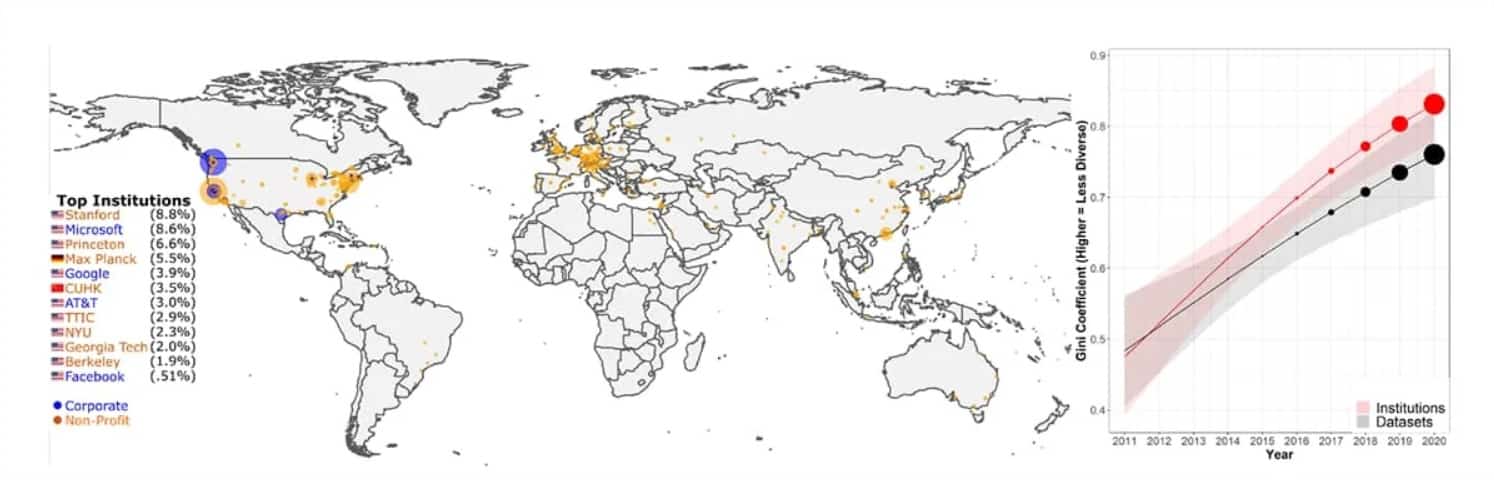
En se basant sur le projet Papers With Code (PWC) initié par Facebook, les auteurs ont découvert que » les datasets les plus largement utilisés sont introduits par une petite poignée d’institutions d’élite « . Au fil des dernières années, cette » consolidation » a augmenté de 80%.
Au sein de l’échantillon de 43 140 usages de datasets passés en revue, plus de 50% ont été créés par douze institutions d’élite principalement occidentales. Parmi ces institutions, on compte la Stanford University, Microsoft, Princeton, Facebook, Google, le Max Planck Institute et AT&T. Sur dix des principales sources de datasets, quatre sont des institutions corporatives.
Les chercheurs veulent battre le benchmark plutôt qu’innover
L’étude qualifie aussi l’usage croissant de ces datasets comme « un véhicule pour l’inégalité dans la science « . Pour cause, les équipes de recherche en quête d’approbation de la communauté seront plus motivées à obtenir de bons résultats sur un dataset populaire qu’à générer des datasets originaux.
De plus, cette pratique forcerait leurs pairs à s’adapter à de nouvelles métriques plutôt qu’aux indices standards. Créer un nouveau dataset est bien trop cher pour les équipes et institutions les plus modestes.
Par conséquent, même dans les situations où un benchmark spécifique serait plus approprié techniquement, les chercheurs préfèrent se tourner vers un dataset de référence. Pour l’équipe à l’origine de cette étude, cette dynamique crée un » Effet Matthieu « : les riches deviennent plus riches, et les pauvres deviennent plus pauvres. Les benchmarks à succès et les institutions d’élite qui les ont créés sont considérés comme les figures de proue du secteur.
Cette culture du » beat-the-benchmark « serait apparue comme un remède au manque d’outils d’évaluation objectifs, ayant causé l’effondrement des investissements dans l’IA il y a 30 ans de cela : le fameux » AI Winter » des années 1980.
Dans un premier temps, cette standardisation a permis de réduire les barrières à la participation, de mettre en place des métriques cohérentes et d’offrir des opportunités pour le développement agile. Toutefois, les inconvénients prennent désormais le dessus sur ces bienfaits.
La communauté de recherche ne cherche plus à résoudre de nouveaux problèmes s’ils ne peuvent pas être abordés avec les benchmarks existants. En outre, les résultats sont souvent » overfitted « puisqu’ils ne seront pas aussi concluants sur des données du monde réel ou sur de nouveaux datasets.
La Computer Vision particulièrement touchée par le phénomène

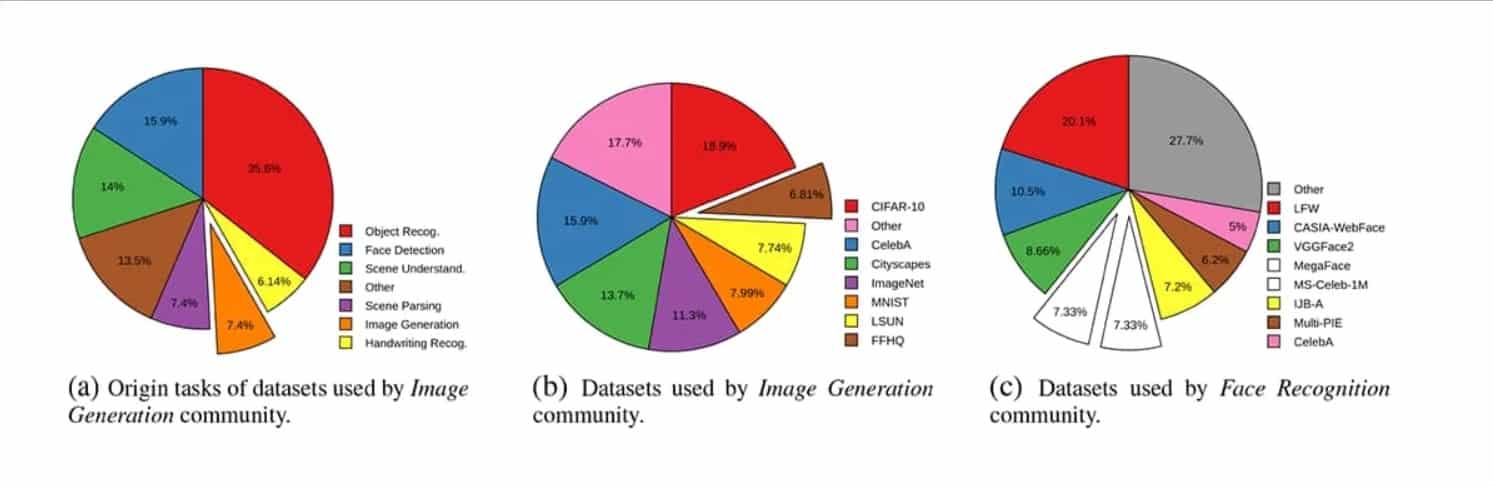
Ce phénomène d’hégémonie touche particulièrement le secteur de la Computer Vision (vision par ordinateur), tandis que le domaine du Natural Langage Processing (NLP) semble beaucoup moins affecté. Selon les auteurs, la raison est que la communauté NLP est bien plus vastes et que les datasets sont plus accessibles, plus petits et moins gourmands en ressources.
Au contraire, dans le domaine de la Computer Vision, et plus particulièrement sur les datasets de reconnaissance faciale, les intérêts des chercheurs entrent souvent en collision avec ceux des entreprises et des gouvernements. Ces derniers sont notamment intéressés par l’usage technologique à des fins de surveillance.
Ainsi, les auteurs de l’étude ont découvert que l’incidence des datasets purement académiques s’est effondrée beaucoup plus que la moyenne. Quatre des huit datasets passés en revue, représentant 33,69% des usages, ont été exclusivement financés par des corporations, par l’armée américaine ou par le gouvernement chinois.
Il s’agit de MS-Celeb-1M, CASIA-Webface, IJB-A et VggFace2. D’ailleurs, MS-Celeb-1M a finalement été retiré à cause d’une controverse autour de la confidentialité.
En outre, le domaine de la Génération d’Image ou Synthèse d’Image, relativement récent, dépend fortement de datasets beaucoup plus anciens qui n’étaient pas conçus pour cet usage à l’origine.
De l’importance de soutenir les institutions modestes
Ce phénomène de migration des datasets hors de leur but initial est de plus en plus fréquent. Ceci pose des questions sur leur pertinence, et sur la façon dont les contraintes budgétaires peuvent » génériser » les ambitions des chercheurs dans un cadre étroit.
Plusieurs experts en Machine Learning appellent depuis longtemps à une meilleure diversité des datasets, dont Andrew NG. Toutefois, les auteurs de l’étude craignent que ces efforts soient torpillés par la dépendance aux résultats et aux datasets populaires.
Afin de lutter contre cette tendance, les chercheurs appellent à prioriser le financement des institutions les moins fortunées pour les aider à créer des ensembles de données de haute qualité. Ceci permettrait une meilleure diversité sociale et culturelle des benchmarks utilisés pour évaluer les méthodes de Machine Learning modernes.
Cette étude intitulée » Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research » a été menée par Bernard Koch et Jacob G. Foster de UCLA, et Emily Denton et Alex Hanna de Google Research.
https://www.youtube.com/watch?v=VMsP9XXyXu8
- Partager l'article :



