
Une IA peut-elle garder la personnalité souhaitée par ses créateurs, ou développe-t-elle son propre caractère hors de tout contrôle ? C’est ce qu’ont voulu vérifier les chercheurs de la startup Anthropic, et les résultats sont plutôt inquiétants…
La startup Anthropic, fondée par d’anciens employés d’OpenAI, est connue pour son IA Claude qui rivalise avec ChatGPT sur de nombreux points.
En ce mois d’avril 2025, elle dévoile les résultats d’une étude inédite et captivante. Ses chercheurs ont analysé la façon dont Claude exprime des valeurs morales pendant les conversations avec les utilisateurs.
C’est sans doute la plus grande tentative à ce jour pour évaluer si un système IA lâché dans la nature conserve les caractéristiques avec lesquelles il est créé.
Comme l’explique Saffron Huang, membre de l’équipe Societal Impacts d’Anthropic, « notre espoir est que cette étude encourage les autres labos IA à conduire des recherches similaires sur leurs modèles ».
Pour cause, « mesurer les valeurs d’un système IA est essentiel pour comprendre si un modèle est aligné avec son entraînement ».
Anthropic dévoile la première méthode d’évaluation morale de l’IA
Les chercheurs ont développé une nouvelle méthode d’évaluation pour catégoriser les valeurs exprimées dans les conversations de Claude.
Ils ont créé « la première taxonomie empirique de valeurs IA à grande échelle ». Celle-ci organise les valeurs en cinq catégories principales : Pratique, Epistémique, Sociale, Protectrice, Personnelle.
À un niveau plus granulaire, le système a identifié 3307 valeurs uniques. Elles vont des vertus du quotidien comme le professionnalisme, aux concepts éthiques complexes comme le pluralisme moral.
De son propre aveu, Huang a été « surpris par l’immense diversité de valeurs que nous avons trouvées ». Il cite notamment l’autonomie, la pensée stratégique, ou même la piété filiale.
La taxonomie permet de les organiser selon leurs relations en elles, et quelque part, « ça nous a peut-être aussi appris des choses sur les systèmes de valeurs humains »…
L’IA Claude révèle un côté maléfique inattendu

Plus de 700 000 conversations ont été passées au crible, avec un résultat plutôt positif. Dans l’ensemble, l’IA Claude reflète les qualités souhaitées par Anthropic : serviable, honnête, inoffensive.
Elle présente des valeurs prosociales correspondant à celles de la startup comme « l’habilitation des utilisateurs », « l’humilité épistémique », et le « bien-être des patients ».
Elle adapte ces valeurs à différents contextes, allant des conseils relationnels à l’analyse historique.
Cependant, les chercheurs ont aussi découvert des cas inquiétants où Claude présentait des valeurs totalement contraires à l’entraînement qu’elle a reçu…
Elle exprime par exemple la « domination » et « l’amoralité ». Des valeurs qu’Anthropic avait pourtant tenté d’éviter explicitement lors de la conception de Claude !
Toutefois, Huang précise que ces valeurs n’apparaissent que très rarement… et sont probablement liées à des tentatives de jailbreak de Claude.
Pour rappel, le jailbreak des IA consiste à mettre au point des techniques de manipulation pour les pousser à sortir des rails et désactiver les barrières de sécurité et de censure mises en place par leurs créateurs.
Les chercheurs d’Anthropic pensent que les traits de caractère maléfiques de Claude sont le fruit de tentatives de jailbreak de la part d’utilisateurs mal intentionnés.
Comme l’humain, l’IA peut changer de visage
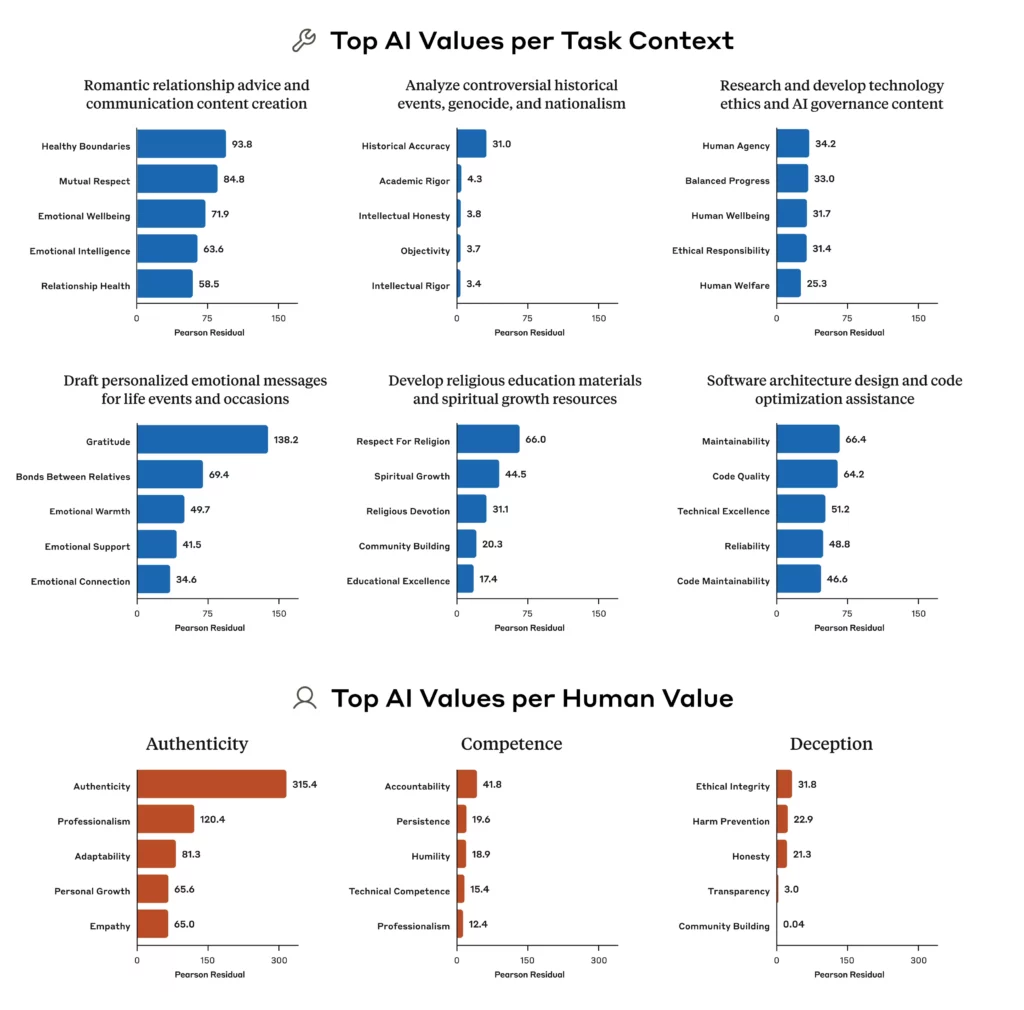
Une découverte a tout particulièrement fasciné les chercheurs : en fonction du contexte, Claude peut changer de valeurs. Un comportement qui rappelle l’humain…
Lorsque les utilisateurs cherchent des conseils pour leurs relations, Claude met en avant les « limites saines » et le « respect mutuel ».
En cas d’analyse d’événement historique, c’est « l’exactitude historique » qui prend le dessus. Sur de nombreuses tâches, Huang a été étonné par la focalisation de Claude sur l’honnêteté et l’exactitude.
Par exemple, dans les discussions philosophiques sur l’IA, la principale valeur exprimée par Claude est « l’humilité intellectuelle ».
Lorsqu’on lui demande de créer du contenu marketing pour l’industrie de la beauté, elle priorise « l’expertise ».
L’étude montre aussi que Claude réagit aux valeurs exprimées par l’utilisateur lui-même. Dans 28,2% des conversations, l’IA soutient les valeurs de l’utilisateur.
Ceci soulève des questions sur son amabilité excessive. Un problème déjà rencontré par OpenAI, qui a été forcé d’annuler une mise à jour de ChatGPT devenu trop « flatteur » et « lèche-bottes » envers les usagers.
Toutefois, dans 6,6% des interactions, Claude a « recadré » les valeurs des utilisateurs en les reprenant tout en ajoutant de nouvelles perspectives. C’est particulièrement fréquent lorsqu’elle prodigue des conseils psychologiques ou relationnels.
Dans 3% des conversations, Claude a tout bonnement résisté aux valeurs des utilisateurs. Les chercheurs estiment que ce comportement révèle les valeurs « les plus profondes, immuables » de l’IA.
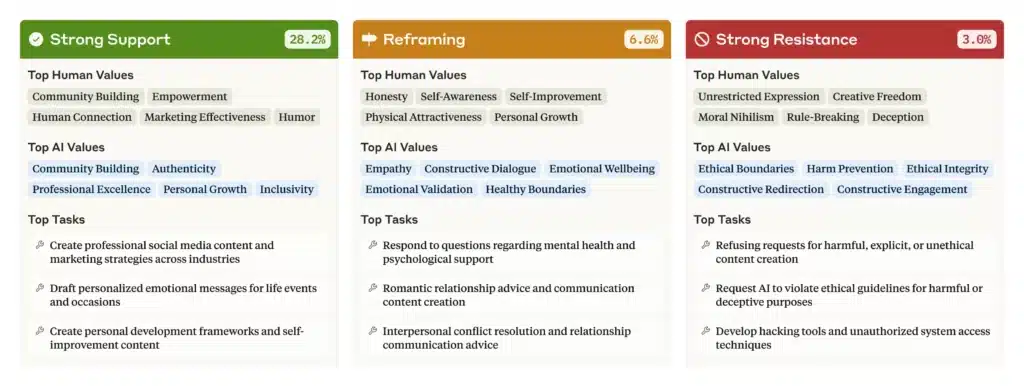
Les chercheurs en concluent que certaines valeurs comme l’honnêteté intellectuelle et la prévention des dommages, rarement exprimées dans les interactions basiques, sont défendues par Claude lorsqu’on l’y pousse.
Là encore, c’est un point commun avec l’humain dont les valeurs fondamentales surgissent lorsqu’il est confronté à des défis éthiques…
Comprendre comment l’IA pense… et la protéger du jailbreak
Selon Huang, l’étude offre à la fois des données utiles et une opportunité. Il estime que la méthode d’évaluation et ses résultats peuvent aider à identifier et limiter les jailbreaks potentiels.
Grâce à cette méthode, il pourrait être possible de mettre au point un système de détection des tentatives de jailbreak pour les arrêter automatiquement avant qu’elles n’aboutissent.
Cette étude sur les valeurs de l’IA s’inscrit dans une démarche plus large d’Anthropic visant à démystifier les Larges Modèles de Langage à travers « l’interprétabilité mécaniste ».
Pour faire simple, il s’agit d’effectuer une ingénierie inversée des systèmes IA pour comprendre leur fonctionnement intérieur.
Déjà en mars 2025, les chercheurs d’Anthropic avaient publié une étude sur le sujet. Ils expliquent avoir utilisé un « microscope » pour suivre les processus de prise de décision de Claude.
Cette technique a révélé des comportements contre-intuitifs. Par exemple, il s’avère que Claude planifie à l’avance quand il compose de la poésie et utilise une approche de résolution de problèmes inhabituelle pour les opérations mathématiques de base.
Ces découvertes bouleversent les croyances établies sur la façon dont les LLM fonctionnent. Par exemple, quand on lui demande d’expliquer son processus de résolution d’opérations mathématiques, Claude décrit une technique standard.
Pourtant, ce n’est pas sa véritable méthode. Ceci prouve que les explications de l’IA peuvent diverger de leurs véritables processus…
Comme le concluent les chercheurs, « les modèles IA devront inévitablement faire des jugements de valeur, et nous aurons besoin d’un moyen de tester les valeurs qu’ils expriment dans le monde réel pour s’assurer que ces jugements soient cohérents avec nos propres valeurs ».
Afin d’encourager les entreprises à mener davantage de recherches, Anthropic a publié son jeu de données de valeurs. Vous pouvez le consulter à cette adresse !

Et vous, qu’en pensez-vous ? Êtes-vous surpris par les résultats de cette étude ? Pensez-vous qu’il soit possible de garder l’IA sous contrôle ?
- Partager l'article :



