Le perceptron est l’un des tout premiers algorithmes de Machine Learning, et le réseau de neurones artificiels le plus simple. Découvrez la définition du perceptron monocouche et multicouche ainsi que son histoire.
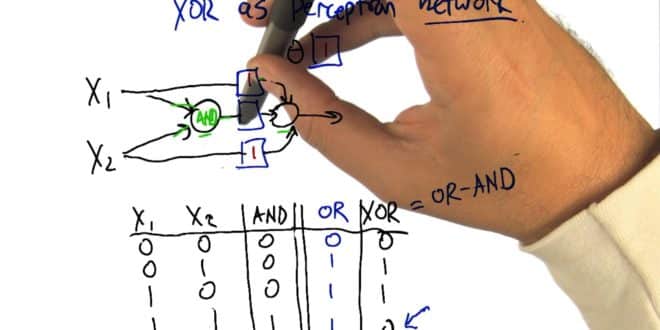
Dans le domaine du Machine Learning, le perceptron est un algorithme d’apprentissage supervisé de classifieurs binaires (séparant deux classes). Il s’agit alors d’un type de classifieur linéaire, et du type de réseau de neurones artificiels le plus simple.
Dans le cas d’un classifieur linéaire, les données d’entraînement doivent être classifiées en catégories correspondantes de sorte que si des classifications sont appliquées à deux catégories, toutes les données d’entraînement doivent être rangées dans ces deux catégories. Dans le cas d’un classifieur binaire, il ne peut y avoir que deux catégories de classification.
Origine et histoire

Frank Rosenblatt inventa l’algorithme en 1957, au sein du Cornell Aeronautical Laboratory. L’United States Office of Naval Research finança les recherches. Les théories cognitives de Friedrich Hayek et Donald Hebb influencèrent son apparition. Initialement, il était censé être une machine plutôt qu’un programme.
Sa première implémentation fut effectuée sous la forme d’un logiciel pour l’IBM 704, mais il a ensuite été implémenté dans une machine créée spécialement pour l’occasion baptisée Mark 1. Cette machine était conçue pour la reconnaissance d’image, et regroupait 400 photocells connectés à des neurones. Les poids synaptiques étaient encodés dans des potentiomètres, et les changements de poids pendant l’apprentissage étaient effectués par des moteurs électriques. Cette machine est l’un des tout premiers réseaux de neurones artificiels.
L’algorithme était conçu pour classifier des inputs visuels, catégoriser des sujets dans un des deux types et séparer les groupes par une ligne. La classification est en effet une part importante du Machine Learning et du traitement d’image. Les algorithmes de Machine Learning trouvent et classifient des patterns de différentes façons. L’algorithme perceptron de son côté classifie les patterns et les regroupe en trouvant la séparation linéaire entre différents objets et patterns reçus par le biais d’inputs visuels ou numériques.
Perceptron multicouche : le réseau neuronal à propagation directe
Lors de sa création, le perceptron apparaissait comme une avancée majeure pour le développement de l’intelligence artificielle. Malheureusement, les limites techniques ont rapidement été atteintes. Pour cause, un perceptron à une seule couche peut uniquement séparer les classes si elles sont séparables de façon linéaire.
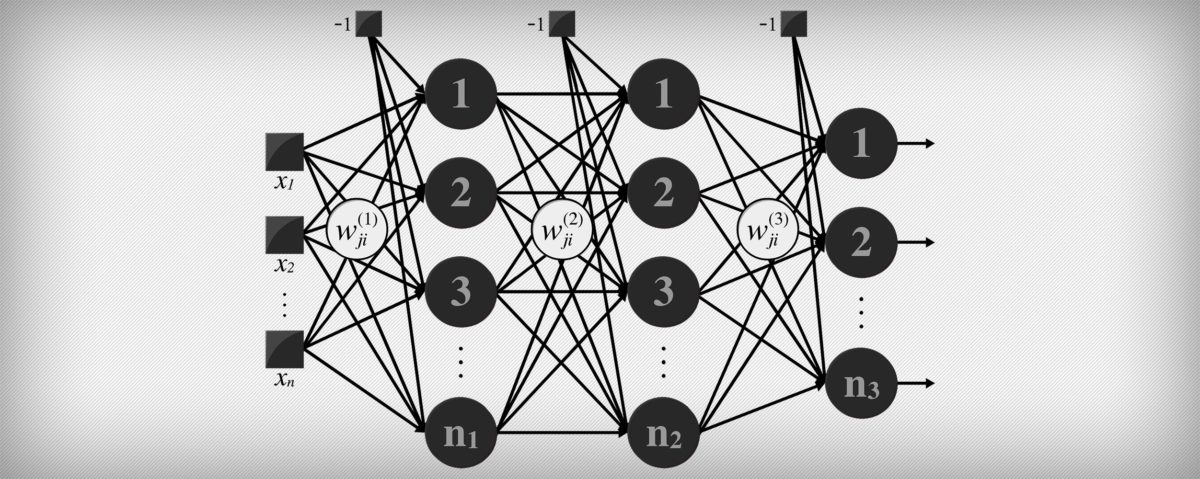
Toutefois, par la suite, il a été découvert qu’un perceptron multicouche pouvait permettre de classifier des groupes qui ne sont pas séparables de façon linéaire. Il permet donc de résoudre des problèmes que les algorithmes à une seule couche ne peuvent résoudre.
Ainsi, un perceptron multicouche (ou multilayer) est un type de réseau neuronal formel qui s’organise en plusieurs couches. L’information circule de la couche d’entrée vers la couche de sortie. Au contraire un modèle monocouche ne dispose que d’une seule sortie pour toutes les entrées.
Il est donc un réseau à propagation directe (feedforward). Chaque couche se compose d’un nombre de neurones variables. Les neurones de la dernière couche sont les sorties du système global.
- Partager l'article :


