
Delta Lake est une solution proposée en open source par Databricks, le créateur original du moteur d'analyse Big Data Apache Spark. Il s'agit d'un outil permettant de rendre les données des Data Lakes plus fiables grâce à une épaisseur de stockage supplémentaire. Découvrez tout ce que vous devez savoir à son sujet.
Un Data Lake, ou lac de données, est un immense répertoire au sein duquel une entreprise stocke toutes les données qu'elle a besoin de traiter. Ceci permet d'unifier de multiples sources de données. Malheureusement, bien souvent, les données stockées au sein des Data Lakes ne sont pas fiables, et les Data Lakes sont eux-mêmes désorganisés.
Qu'est-ce Delta Lake et à quoi ça sert ?
C'est pourquoi Databricks, fondée par les développeurs du célèbre moteur d'analyse Big Data Apache Spark, a décidé de lancer en open source sa solution propriétaire Delta Lake. L'annonce a été faite dans le cadre du Spark + AI Summit de San Francisco, et le CEO de Databricks, Ali Ghodsi, annonce qu'il s'agit d'une innovation plus importante encore que Spark.
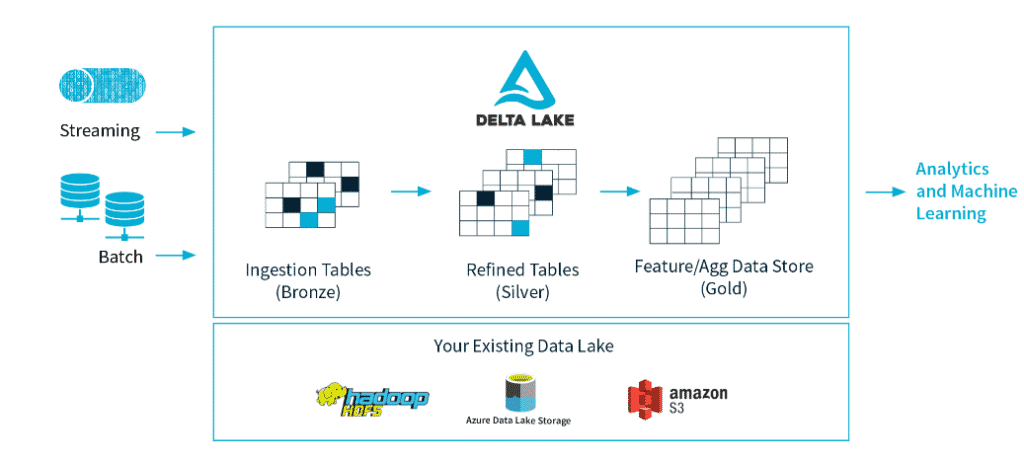
Delta Lake est une couche de stockage ajoutée par-dessus le Data Lake afin d'offrir des sources de données fiables pour le Machine Learning et la science des données. L'outil passe en revue toutes les données entrantes, et s'assure qu'elles correspondent au schéma mis en place par l'utilisateur. Ceci permet de s'assurer que les données soient fiables et correctes.
Une transaction ACID est ajoutée à chaque opération effectuée, afin de s'assurer que les opérations soient toujours correctes. Ainsi, il n'est plus possible d'être confronté à une erreur ou à des données incomplètes.
En outre, le Delta Lake est compatible avec les APIs Apache Spark. Ceci lui permet notamment de prendre en charge les métadonnées du lac de données.
Delta Lake peut fonctionner sur des serveurs sur site, sur le Cloud, ou sur des appareils tels que des laptops. Il est compatible avec les sources de données en batch ou en streaming.
Dans un avenir proche, DataBricks compte aussi ajouter une fonctionnalité permettant d'accéder à d'anciennes versions des données pour des audits ou pour reproduire des expériences de Machine Learning MLFlow.
Les avantages de Delta Lake à disposition de tous les Data Lakes
Depuis un an, Delta Lake était déjà fourni par Databricks à près d'un millier de grandes entreprises comme Viacom, Edmunds, Riot Games et McGraw Hill. La firme assure que sa solution a permis à des centaines d'entreprises de surmonter les défis liés aux Data Lakes traditionnels.
Désormais, toutes les entreprises vont pouvoir profiter de ses bénéfices. Grâce à l'open-sourcing de Delta Lake, les développeurs seront en mesure de construire facilement des Data Lakes et de les transformer en » Delta Lakes « pour une fiabilité accrue. En effet, il est important de souligner à nouveau que Delta Lake peut être exécuté par-dessus n'importe quel Data Lakes existant.
Pour le futur, Databricks hésite encore sur la façon dont le projet sera gouverné. Il est probable que Delta Lake soit proposé sur Github, afin de pouvoir recevoir de nombreuses contributions tout en restant gouverné convenablement. Quel que soit le mode de gouvernance choisi, Databricks a pour priorité de fédérer une large communauté autour de son projet afin de maximiser la fiabilité des données dans les Data Lakes.
C'est d'ailleurs pourquoi la firme a fait le choix de proposer sa solution sous la licence Apache License V2, au même titre qu'Apache Spark. Cette licence permissive a été préférée à la licence Commons Clause, qu'utilisent de nombreuses entreprises open-source pour empêcher les grands fournisseurs de Cloud d'intégrer leurs outils à leurs propres offres SaaS commerciales.
Databricks souhaite que sa technologie Delta Lake soit utilisée par les entreprises de toutes les tailles, sur site et sur le Cloud. Son objectif est que Delta Lake devienne un nouveau standard pour le stockage de Big Data…
https://www.youtube.com/watch?v=5I5pqDsvGEc
- Partager l'article :


