
14 millions d’échantillons viennent d’être publiés par la section de recherche en IA d’IBM. Cette initiative a pour objectif de déployer des modèles d’apprentissage automatique qui serviront à programmer diverses tâches. Intitulée Project CodeNet, cette appellation rend hommage au fameux référentiel d’images étiquetées ImageNet.
Une lueur d’espoir pour les développeurs humains
Il faut être réaliste. Ce produit d’apprentissage automatique est, certes, fondé par IBM sur l’intégralité des données CodeNet. Toutefois, les chances qu’il prenne la place des programmeurs quitte à les rendre obsolètes restent minces. Dans tous les cas, ce modèle a l’avantage d’influer positivement sur la productivité des développeurs.
Normaliser la programmation grâce à l’intelligence artificielle
Les progrès surprenants rencontrés au sein de l’apprentissage automatique datent de 2010. Dès lors, l’engouement de l’homme par rapport à l’intelligence artificielle n’a cessé de croître. Elle permet effectivement de robotiser plusieurs activités. Parmi celles-ci, s’affichent la programmation. Cependant, l’intégration de l’IA dans l’élaboration des logiciels demeure limitée. Les experts en programmation rencontrent effectivement de nouveaux obstacles. Afin de contourner ces difficultés, ils se lancent dans l’exploration de solutions de tous genres. Cela inclut l’utilisation excessive de la matière grise. En ce qui concerne les algorithmes d’apprentissage automatique, ces derniers requièrent des problèmes définis ainsi qu’une pléthore de données. Cela servira à concevoir des modèles efficients, aptes à résoudre des problèmes identiques.
IBM s’investit pleinement dans le projet CodeNet
De nombreux efforts ont été fournis afin de pouvoir développer des procédures « IA pour code ». Néanmoins, élaborer un ensemble de données taillé pour une programmation reste assez compliqué.
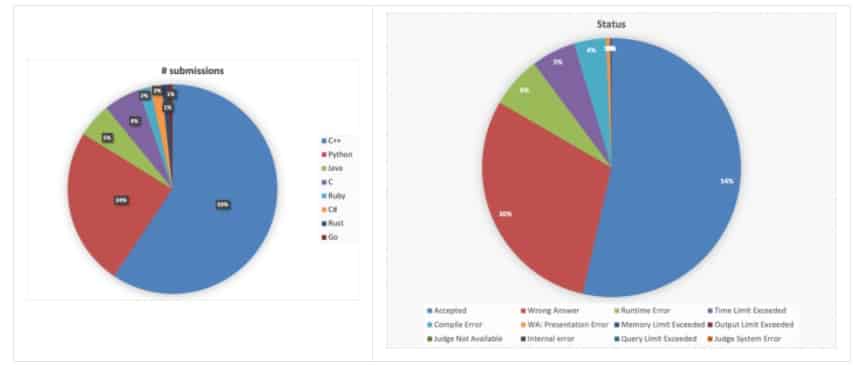
Les attentes des chercheurs d’IBM vis-à-vis du projet CodeNet sont conséquentes. En effet, ils ont cherché à créer un ensemble de données polyvalent. Ces datas seront exploitées pour constituer des modèles d’apprentissage automatiques destinés à réaliser des tâches. Pour le fondateur de CodeNet, il s’agit d’un « ensemble de données à très grande échelle, diversifié et de haute qualité pour accélérer les progrès algorithmiques de l’IA pour le code ». Celui-ci recèle 14 millions d’échantillons de code. Il possède, par ailleurs, 500 millions de lignes de code qui sont transcrites sous 55 langages différents de la programmation. Ces modèles ont été acquis grâce à des soumissions obtenues sur près de 4 000 défis que l’on a publié sur les interfaces de codage en ligne AtCoder et AIZU. Les exemples de code présentent aussi bien des résultats corrects qu’incorrects aux défis proposés.
- Partager l'article :



