
Apache Hive est la Data Warehouse de Apache Hadoop. Découvrez tout ce que vous devez savoir à son sujet : définition, cas d’usage, fonctionnement, avantages…
Le framework open-source Hadoop se révèle idéal pour le stockage et le traitement de quantités massives de données. En revanche, pour l’extraction de données, cette plateforme se révèle inutilement complexe, chronophage et coûteuse. Fort heureusement, la fondation Apache propose une autre solution pour remédier à ce problème : Apache Hive.
Apache Hive : qu’est-ce que c’est et à quoi ça sert ?

Apache Hive est un logiciel de Data Warehouse initialement créé par Facebook. Il permet d’effectuer facilement et rapidement des requêtes » SQL-like « pour extraire efficacement des données en provenance de Apache Hadoop. Contrairement à Hadoop, Hive permet d’effectuer des requêtes SQL sans avoir besoin d’écrire en Java.
Aujourd’hui, l’interface » SQL-like » d’Apache Hive est devenue la solution la plus populaire pour effectuer des requêtes et analyser les données Hadoop. Il s’agit d’une solution économique et pouvant être scalée via le Cloud. C’est pourquoi de nombreuses entreprises comme Netflix et Amazon utilisent et contribuent à améliorer Hive.
Apache Hive : comment ça marche ?
Pour faire simple, Apache Hive traduit les programmes rédigés en langage HiveQL (SQL-like) en une ou plusieurs tâches Java MapReduce, Tez ou Spark (trois moteurs d’exécution pouvant être lancés sur Hadoop YARN). Par la suite, Hive organise les données en tableau pour le fichier Hadoop Distributed File System (HDFS) et exécute les tâches sur un cluster pour produire une réponse.
Les tableaux Apache Hive sont similaires à ceux d’une base de données relationnelle, et les unités de données sont organisées de l’unité la plus large à la plus granulaire. Les bases de données sont constituées de tableaux composés de partitions, pouvant à nouveau être décomposées en » buckets « . Les données sont accessibles via HiveQL. Au sein de chaque base de données, les données sont numérotées et chaque tableau correspond à un répertoire HDFS.
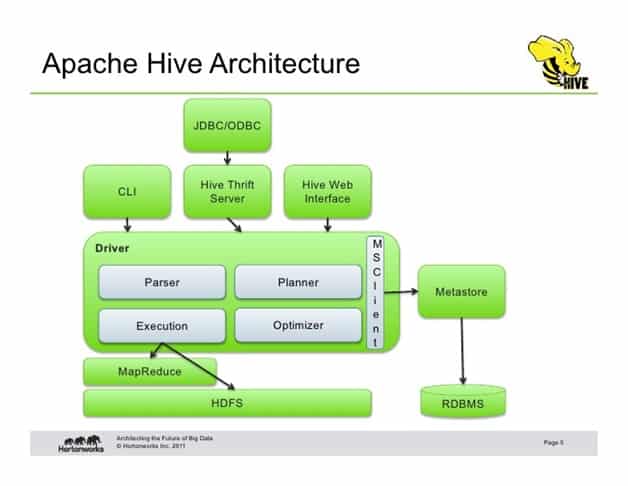
Au sein de l’architecture d’Apache Hive, de multiples interfaces sont disponibles : interface web, CLI, clients externes… le serveur Apache Hive Thrift permet aux clients distants de soumettre des commandes et des requêtes à Apache Hive en utilisant divers langages de programmation. Le répertoire central d’Apache Hive est un metastore contenant toutes les informations.
Le moteur permettant le fonctionnement de Hive est le pilote. Il regroupe un compilateur, un optimisateur pour déterminer le meilleur plan d’exécution, et un exécuteur.
Enfin, la sécurité est assurée par Hadoop. Elle repose donc sur Kerberos pour l’authentification mutuelle entre le client et le serveur. Les permissions pour les fichiers nouvellement créés dans Apache Hive sont dictées par HDFS, qui permet l’autorisation par utilisateur, groupe ou autre.
Apache Hive : quels sont les avantages ?
Apache Hive est une solution idéale pour les requêtes had-hoc et les analyses de données. Elle permet donc d’obtenir des insights procurant un avantage compétitif et facilitant la réaction face à la demande du marché.
Parmi les principaux avantages de Hive, on peut citer la simplicité d’utilisation liée à son langage » SQL-like « . En outre, ce logiciel accélère l’insertion initiale de données puisque les données n’ont pas besoin d’être lues et numérotées sur un disque dans le format interne de la base de données. En effet Apache Hive lit le schéma sans vérifier le type de tableau ou la définition du schéma alors qu’une base de données traditionnelle doit vérifier les données chaque fois qu’elles sont insérées.
Sachant que les données sont stockées dans le HDFS, il est possible de stocker des centaines de petabytes de données sur Apache Hive. De fait, cette solution est bien plus scalable qu’une base de données traditionnelle. Sachant qu’il s’agit d’un service Cloud,Hive permet aux utilisateurs de lancer rapidement des serveurs virtuels en fonction des fluctuations de workloads.
La sécurité est au rendez-vous, avec la possibilité de répliquer les workloads critiques pour la restauration en cas de désastre. Enfin, la capacité de travail est hors pair puisqu’il est possible d’effectuer jusqu’à 100 000 requêtes par heure.
- Partager l'article :



