
À l’heure actuelle, Hadoop est la principale plateforme du Big Data. Utilisé pour le stockage et le traitement d’immenses volumes de données, ce framework logiciel et ses différents composants sont utilisés par de très nombreuses entreprises pour leurs projets Big Data. En parcourant ce dossier, vous saurez tout sur Hadoop et son fonctionnement.
Hadoop définition
Hadoop est un framework logiciel open source permettant de stocker des données, et de lancer ds applications sur des grappes de machines standards. Cette solution offre un espace de stockage massif pour tous les types de données, une immense puissance de traitement et la possibilité de prendre en charge une quantité de tâches virtuellement illimitée. Basé sur Java, ce framework fait partie du projet Apache, sponsorisé par Apache Software Foundation.

Grâce au framework MapReduce, il permet de traiter les immenses quantités de données. Plutôt que de devoir déplacer les données vers un réseau pour procéder au traitement, MapReduce permet de déplacer directement le logiciel de traitement vers les données.
L’Histoire de Hadoop
Lors de l’avènement du World Wide Web à la fin des années 90 et au début des années 2000, les moteurs de recherche et les index furent créés pour aider à localiser des informations pertinentes au sein de contenus textuels. Au départ, les résultats de recherche étaient renvoyés par des humains. Bien entendu, lorsque le nombre de pages a augmenté à plusieurs dizaines de millions, l’automatisation est devenue nécessaire. Les web crawlers ont alors été créés, principalement en tant que projets de recherche universitaires. Les moteurs de recherche comme Yahoo et AltaVista ont également commencé à apparaître.
Parmi ces moteurs de recherche, le projet open source Nutch fut créé par Doug Cutting et Mike Cafarella. Leur objectif était de proposer des résultats de recherche web plus rapidement en distribuant des données et des calculs sur différents ordinateurs pour accomplir des tâches multiples simultanément. Dans le même temps, le moteur de recherche Google était en développement. Ce projet était basé sur le même concept de stockage et de traitement de données d’une façon distribuée et automatisée pour proposer des résultats de recherche plus rapidement.

En 2006, Cutting a décidé de rejoindre Yahoo et a emporté avec lui le projet Nutch et les idées basées sur les premiers travaux de Google en termes de traitement et de stockage de données distribués. Le projet Nutch fut divisé en plusieurs parties. Les web crawlers gardèrent le nom Nutch, tandis que le calcul et le traitement distribués devinrent Hadoop (du nom de la peluche d’éléphant jaune du fils de Cutting).
En 2008, Yahoo proposa Hadoop sous la forme d’un projet Open Source. Aujourd’hui, le framework et son écosystème de technologies sont gérés et maintenus par l’association non lucrative Apache Software Foundation, une communauté mondiale de développeurs de logiciels et de contributeurs.
Après quatre ans de développement au sein de la communauté Open Source, Hadoop 1.0 fut proposé au public à partir de novembre 2012 dans le cadre du projet Apache, sponsorisé par la Apache Software Foundation. Depuis lors, le framework n’a cessé d’être développé et mis à jour.
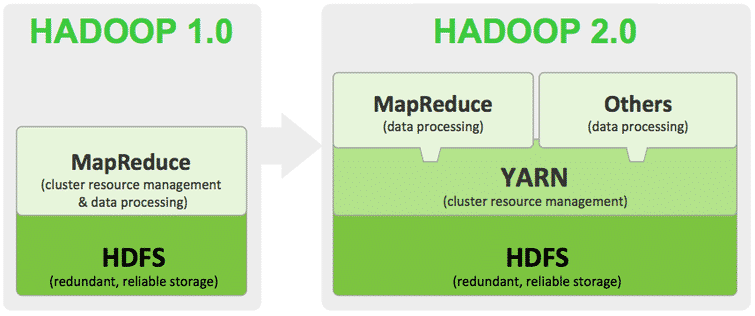
La version deuxième version Hadoop 2 a permis d’améliorer la gestion de ressource et la planification. Elle comporte une option de système fichier à haute disponibilité, et prend en charge Microsoft Windows et d’autres composants afin d’étendre la polyvalence du framework pour le traitement et l’analyse de données. Hadoop est actuellement proposé en version 2.6.5.
Les entreprises peuvent déployer les composants Hadoop et les packages de logiciels compatibles dans leur Data Center local. La plupart des projets Big Data reposent toutefois sur un usage à court terme de ressources informatiques substantielles. Ce type d’utilisation est davantage adapté à des services de Cloud public hautement scalables, comme Amazon Web Sevices, Google Cloud Platform et Microsoft Azure.
Les fournisseurs de services Cloud prennent généralement en charge les composants Hadoop au travers de services basiques, comme AWS Elastic Compute Cloud et Simple Storage Services. Il existe également des services conçus sur mesure pour les tâches Hadoop, comme AWS Elastic MapReduce, Google Cloud Dataproc et Microsoft Azure HDInsight.
Pourquoi Hadoop est important ?
Les avantages apportés aux entreprises par Hadoop sont nombreux. Grâce à ce framework logiciel, il est possible de stocker et de traiter de vastes quantités de données rapidement. Face à l’augmentation en hausse du volume de données et à leur diversification, principalement liée aux réseaux sociaux et à l’internet des objets, il s’agit d’un avantage non négligeable.

De même, le modèle de calcul distribué d’Hadoop permet de traiter rapidement le Big Data. Plus le nombre de nœuds de calcul utilisés est important, plus la puissance de traitement est élevée. Les données et les applications traitées sont protégées contre les échecs hardware. Si un nœud tombe en panne, les tâches sont directement redirigées vers d’autres nœuds pour s’assurer que le calcul distribué n’échoue pas. De multiples copies de toutes les données sont stockées automatiquement.
Contrairement aux bases de données relationnelles traditionnelles, il est inutile de traiter les données au préalable avant de les stocker. Il est possible de stocker autant de données que vous le souhaitez et décider plus tard de la manière de les utiliser. Ceci regroupe les données non structurées comme le texte, les images et les vidéos.
Le framework open source est donc gratuit et repose sur des machines standards pour stocker de larges quantités de données. Enfin, il est possible d’adapter le système pour prendre en charge plus de données en ajoutant simplement des nœuds. L’administration requise est minimale.
Quels sont les défis liés à l’utilisation de Hadoop ?

La programmation de MapReduce n’est pas adaptée à tous les problèmes. Elle convient aux requêtes d’information simples et aux problèmes pouvant être divisés en unités indépendantes. En revanche, elle n’est pas efficace pour les tâches analytiques itératives et interactives. Les nœuds ne communiquent pas entre eux, et les algorithmes itératifs requièrent de multiples phases de map-shuffle et de tri pour compléter leurs tâches. De nombreux fichiers sont créés entre les phases MapReduce, et cette programmation ne convient pas pour les calculs analytiques avancés.
Il existe un large fossé de talent. Il est très difficile de trouver des programmeurs suffisamment compétents en Java pour être productifs avec MapReduce. C’est l’une des raisons pour lesquelles les fournisseurs de distribution cherchent à placer les technologies relationnelles SQL au sommet d’Hadoop. Il est plus facile de trouver des programmeurs dotés de compétences SQL que des experts en MapReduce. De plus, l’administration semble à la fois artistique et scientifique, et requiert peu de connaissance en systèmes d’exploitation, en hardware et en paramètres des kernels Hadoop.
Un autre challenge concerne les problèmes de sécurité des données fragmentées, même si de nouveaux outils et technologies sont en train d’émerger. Le protocole d’authentification Kerberos représente un pas en avant dans la sécurisation des environnements du framework
Enfin, il n’existe pas d’outil intuitif et complet pour la gestion de données sur Hadoop. Il en va de même pour le nettoyage, la gouvernance de données et les métadonnées. Les outils les plus manquants sont ceux relatifs à la qualité et à la standardisation des données.
De quelle façon Hadoop est utilisé par les entreprises ?

De nos jours, au-delà de sa fonctionnalité initiale visant à chercher des millions de pages web pour obtenir des résultats pertinents, Hadoop est utilisé par de nombreuses entreprises en guise de plateforme Big Data. Voici les principaux usages d’Hadoop en entreprise à l’heure actuelle :
Le stockage low-cost et l’archive de données
Le coût modeste des machines standards rend cette plateforme de traitement de données très utile pour le stockage et la combinaison de données. Les données transactionnelles, ou les données en provenance de réseaux sociaux, de machines, les données scientifiques, les flux de clics… le stockage low-cost permet de garder les informations qui ne sont pas spécialement utiles à l’heure actuelle au cas où elles le deviendraient plus tard.
Un bac à sable pour la découverte et l’analyse
Conçu pour traiter de vastes volumes de données de différentes formes, Hadoop est capable de gérer des algorithmes analytiques. Les outils analytiques peuvent aider l’entreprise à opérer plus efficacement, à découvrir de nouvelles opportunités, et à obtenir des avantages compétitifs. L’approche bac à sable d’Hadoop offre des opportunités pour l’innovation moyenne un investissement minimal.
Data Lake
Les Data Lakes prennent en charge le stockage de données dans le format original. L’objectif est d’offrir une vue brute et non raffinée des données à destination des data scientists et des analystes pour la découverte et l’analyse. Ceci les aide à poser de nouvelles questions ou des questions complexes sans contraintes. Les Data Lakes ne sont toutefois pas un remplacement pour les Data Warehouses. La façon de sécuriser et de gouverner les Data Lakes reste aujourd’hui un grand débat dans l’industrie informatique. Il faudrait éventuellement développer des structures de données logiques en se basant sur les techniques de fédération de données.
Complémenter les Data Warehouses
Actuellement, Hadoop siège à côté des environnements Data Warehouse. De même, certains ensembles de données sont déchargés directement depuis les Data Warehouses vers Hadoop, et certains nouveaux types de données vont directement sur Hadoop. L’objectif final de chaque entreprise est d’avoir la bonne plateforme pour stocker et traiter des données de différents schémas et formats afin de prendre en charge différents cas d’usage pouvant être intégrés à différents niveaux.
Hadoop et l’Internet des Objets
Les objets connectés doivent savoir ce qu’ils doivent communiquer et quand agir. L’essence de l’internet des objets est le streaming continu de données. Hadoop est souvent utilisé comme un data store pour des milliards de transactions. Le stockage massif et les capacités de traitement permettent également d’utiliser la plateforme Big Data en guise de bac à sable pour la découverte et la mise en place de patterns pour l’instruction prescriptive. Il est ensuite possible d’améliorer continuellement ces instructions, car Hadoop est mis à jour en permanence à l’aide de nouvelles données.
Moteur de recommandations
L’une des utilisations d’Hadoop les plus populaires est la création de systèmes de recommandation sur le web. De nombreuses entreprises utilisent les outils analytiques du framework pour fournir ce type de services. Facebook s’en sert pour vous suggérer des personnes que vous pourriez connaitre, LinkedIn vous propose des emplois qui pourraient vous intéresser, tandis que Netflix, eBay et Hulu vous recommandent du contenu. Ces systèmes de recommandation analysent de grandes quantités de données en temps réel pour prédire rapidement les préférences des consommateurs avant qu’ils n’aient le temps de quitter la page web.

Un système de recommandation s’occupe de générer un profil d’utilisateur de façon explicite, en demandant des informations à l’usager, ou implicite, en observant son comportement. Ce profil est ensuite comparé à des caractéristiques références, basées sur des observations de la communauté entière des utilisateurs. Le système peut ainsi proposer des suggestions pertinentes.
Comment ça marche ? Un inventaire d’outils pour un tutoriel Hadoop
On dénombre à l’heure actuelle quatre modules principaux inclus dans le framework Hadoop de base d’Apache Foundation. Hadoop Common rassemble les bibliothèques et les utilitaires utilisés par les autres modules. Le Hadoop Distributed File System (HDFS) est un système scalable basé sur le Java permettant de stocker des données sur de nombreuses machines sans organisation préalable. Le YARN (Yet Another Resource Negotiator) permet de gérer les ressources pour les processus effectués sur la plateforme. Enfin, MapReduce est un framework logiciel de traitement parallèle. Il regroupe deux étapes. L’étape Map permet de récupérer des entrées pour les répartir en sous-problèmes plus petits et les distribuer sur les autres nœuds. Par la suite, le nœud master combine les réponses à tous les sous-problèmes pour produire un résultat.
En dehors de ces quatre modules principaux, différents composants basés sur le framework ont atteint un haut niveau de réputation parmi les projets Apache :
_ Ambari est une interface web pour gérer configurer et tester les services et composants Hadoop.
_ Cassandra est un système de base de données distribué

_ Flume est un logiciel qui collecte, agrège et déplace de larges quantités de flux de données sous HDFS.
_ HBase est une base de données distribuée non relationnelle qui fonctionne par dessus Hadoop. Ses tableaux peuvent servir d’entrée et de sortie pour des tâches MapReduce.
_ HCatalog est outil de gestion de stockage et de tableau permettant aux usagers de partager et d’accéder aux données.
_ Hive est un entrepôt de données et un langage de requête SQL présentant les données sous forme de tableaux. La programmation de Hive est similaire à la programmation d’une base de données.

_ Oozie permet de planifier les tâches du framework.
_ Pig est une plateforme permettant de manipuler les données stockées dans HDFS, et intègre un compilateur pour les programmes MapReduce ainsi qu’un langage de haut niveau baptisé Pig Latin. Il offre un moyen d’effectuer des extractions, des transformations et des chargements de données, mais aussi des analyses basiques sans avoir à écrire des programmes MapReduce.
_ Solr est un outil de recherche scalable permettant notamment l’indexage, la configuration centrale, et la restauration.
_Hadoop Spark est un framework de computing cluster open-source doté d’outils analytics in-memory

_ Sqoop est un mécanisme de connexion et de transfert permettant de déplacer les données entre Hadoop et les bases de données relationnelles.
_ Zookeeper est une application pour coordonner les traitements distribués.
Les distributions commerciales
Le logiciel Open Source est créé et maintenu par un réseau de développeurs venus du monde entier. Il est proposé gratuitement au téléchargement. Il suffit de taper sur son moteur de recherche » Hadoop Telecharger » pour trouver des distributions gratuites. Tout un chacun peut contribuer à son développement et l’utiliser. Cependant, de plus en plus de versions commerciales du framework (souvent surnommées « distros ») sont disponibles.

Distribuées par des vendeurs de logiciels, ces versions payantes proposent un framework Hadoop personnalisé. Les acheteurs bénéficient également de fonctionnalités supplémentaires relatives à la sécurité, à la gouvernance, au SQL, aux consoles de gestion/administration, mais aussi des formations, de la documentation et d’autres services. Parmi les distributions les plus populaires, on compte Cloudera, Hortonworks, MapR, IBM BigInsights et PivotalHD.
Comment entrer des données dans Hadoop ?
Il existe plusieurs façons d’entrer des données dans Hadoop. Vous pouvez utiliser des connecteurs de vendeurs tiers. Il est possible d’utiliser Sqoop pour importer des données structurées à partir d’une base de données relationnelle vers HDFS, Hive, et HBase. Flume permet de charger des données depuis les logs vers Hadoop en continu. Les fichiers peuvent aussi être chargés vers le système à l’aide de simples commandes Java. HDFS peut aussi être monté comme système de fichiers au sein duquel les fichiers peuvent être copiés. Il s’agit là de quelques méthodes parmi les nombreuses options existantes.
Quel avenir pour Hadoop ?
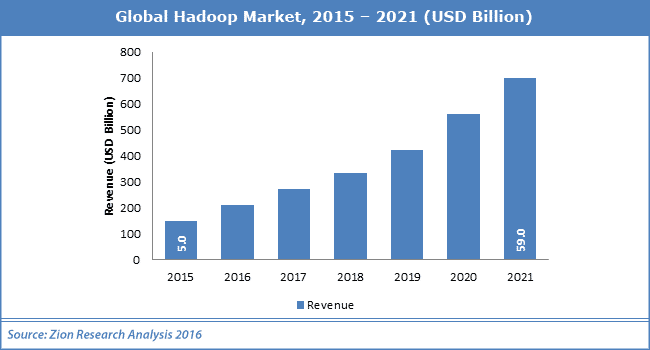
Selon une étude récemment menée par Zion Research, le marché mondial d’Hadoop valait 5 milliards de dollars en 2015, et pourrait atteindre une valeur de 59 milliards de dollars en 2021, avec une croissance annuelle de 51% entre 2016 et 2021.
L’augmentation du volume de données structurées et non structurées au sein des grandes entreprises, et la volonté des entreprises d’utiliser ces données, sont les principaux facteurs de la croissance du marché de la plateforme de traitements distribués. Les secteurs de la santé, de la finance, de la fabrication, de la biotechnologie et la défense ont besoin de solution efficaces et rapides pour surveiller les données. Le développement et les mises à jour du framework pourraient ouvrir de nouvelles opportunités pour le marché. Cependant, les problèmes de sécurité et de distribution pourraient limiter l’utilisation de la plateforme de traitements distribués.
Le logiciel, le hardware et les services sont les trois segments principaux du marché Hadoop. Parmi ces trois segments, celui des services a dominé le marché en 2015 et a généré environ 40% du revenu total. Les services devraient continuer à dominer jusqu’à 2020. Le segment du logiciel devrait également connaitre une importante croissance grâce à l’adoption massive de Hadoop par les grandes entreprises.
L’industrie de l’informatique a représenté 32% du revenu total d’Hadoop en 2015. Vient ensuite l’industrie des télécommunications, puis celles du gouvernement et du retail. Ces derniers secteurs devraient générer une forte croissance car les entreprises adoptent de plus en plus les solutions Hadoop.
L’Amérique du Nord est le principal marché Hadoop en 2015, avec 50% du revenu global généré par le framework. Cette tendance devrait continuer dans les années à venir. L’Asie Pacifique est la région au sein de laquelle le rencontre la plus grande croissance grâce à l’émergence des industries des télécommunications et de l’informatique en Chine et en Inde. L’Europe devrait également initier une forte croissance.
Parmi les principales entreprises du marché, on compte notamment Amazon Web Services, Teradata Corporation, Cisco Systems, IBM Corporation, Cloudera, Inc., Datameer, Inc., Oracle Corporation, Hortonworks, Inc., VMware, OpenX.
Hadoop 2 Vs Hadoop 3
Disponible depuis 2012, Hadoop 2 a été étoffé et au fur et à mesure des années. La dernière version 2.90 est disponible depuis le 17 novembre 2017. En parallèle, la release 3.0.0 est sortie le 13 décembre 2017. Cette nouvelle version apporte son lot de nouveautés qu’il convient de présenter.
La première différence provient de la gestion des conteneurs. La troisième apporte davantage d’agilité grâce à l’isolation des paquets de Docker. Cela permet de créer des applications rapidement et de les déployer en quelques minutes. Ainsi, le Time to Market est plus court.
Le coût d’utilisation d’Hadoop 3 est également plus faible. La deuxième version demande plus d’espace de stockage. Là où la troisième version demande 9 blocs de stockage, la deuxième occupe jusqu’à 18 blocs au total en comptant les copies. La dernière release permet donc de réduire la charge de stockage tout en maintenant la même qualité de sauvegarde des données. Et qui dit moins d’espace occupé, dit réduction des coûts.
Autre différence majeure, Hadoop 2 ne gère qu’un seul namenode. Cet outil de gestion de l’arborescence du système de fichiers, les métadonnées des fichiers et les répertoires. La version suivante peut en gérer plusieurs, ce qui permet d’augmenter de manière exponentielle la taille des infrastructures. Plus de namenodes veut également dire plus de sécurité. Si l’un de ces gestionnaires est « down », un autre peut prendre le relais.
Avec son système d’équilibrage de stockage intra-nœuds, il n’y a plus de problème de déséquilibre dans l’utilisation des disques durs avec Hadoop 3. La répartition des tâches est également plus aisée. Contrairement à la deuxième version il est possible de prioriser les applications et les utilisateurs.
Enfin, cette dernière version du système HDFS ouvre de nouvelles perspectives pour les concepteurs d’algorithmes de machine learning et de deep learning. En effet, elle prend en charge davantage de disque dur, mais surtout les cartes graphiques. Les analyses sont ainsi améliorées par la puissance de calcul de ces processeurs particulièrement utile afin de développer des applications d’intelligence artificielle.
En savoir plus sur Hadoop
- Cluster Hadoop : tout comprendre sur les grappes de serveurs
- Comparatif Hadoop : top 7 des vendeurs commerciaux de distributions
- MapReduce : tout savoir sur le framework Hadoop de traitement Big Data
- Déployer Hadoop, un véritable calvaire selon les experts
- [Startup Tour] Pachyderm, une alternative au célèbre Hadoop pour le traitement de données
- Partager l'article :




j’enseigne le Bigdata et je prepare un cours sur l’ecosysteme hadoop
je suis intresée par cette article
super merci madame