
HDFS est le système de fichier distribué de Hadoop Apache. Il s’agit d’un composant central du Framework de Apache, et plus précisément de son système de stockage. Découvrez le fonctionnement, les avantages et les inconvénients de HDFS.
HDFS (Hadoop Distributed File System) est un système de fichier distribué permettant de stocker et de récupérer des fichiers en un temps record. Il s’agit de l’un des composants basiques du framework Hadoop Apache, et plus précisément de son système de stockage. HDFS Hadoop compte parmi les projets « top level » de Apache.
HDFS définition
De par sa capacité massive et sa fiabilité, HDFS est un système de stockage très adapté au Big Data. En combinaison avec YARN, ce système augmente les possibilités de gestion de données du cluster HDFS Hadoop et permet donc de traiter le Big Data efficacement. Parmi ses principales fonctionnalités, on compte la possibilité de stocker des terabytes, voire des petabytes de données.
Le système est capable de gérer des milliers de nœuds sans intervention d’un opérateur. Il permet de bénéficier simultanément des avantages du computing parallèle et du computing distribué. Après une modification, il permet de restaurer facilement la précédente version d’une donnée.
HDFS peut être lancé sur commodity hardware, ce qui le rend très tolérant aux erreurs. Chaque donnée est stockée à plusieurs endroits, et peut donc être récupérée en toutes circonstances. De même, cette réplication permet de lutter contre la corruption potentielle des données.
Les serveurs sont connectés et communiquent par le biais de protocoles TCP. Même s’il est conçu pour les bases de données massives, les systèmes de fichiers normaux comme FAT et NTFS sont également compatibles. Enfin, une fonctionnalité CheckpointNode permet de vérifier le statut des nœuds en temps réel.
Comment fonctionne HDFS ?
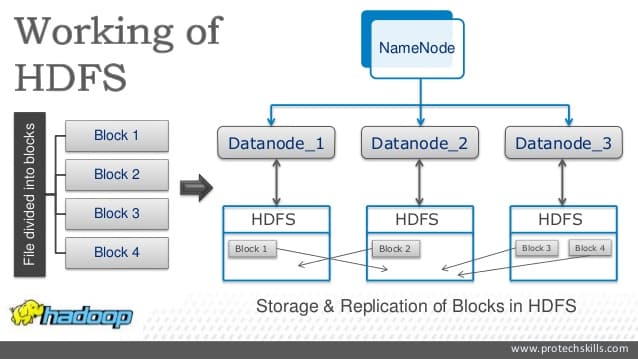
Voici un tutoriel pour HDFS. Le Hadoop Distributed File System repose sur une « architecture HDFS maître/esclave ». Chaque cluster comporte un Namenode individuel faisant office de serveur principal. Ainsi, les clients peuvent accéder aux bonnes données au bon moment. Le Namenode se charge également d’ouvrir, fermer, renommer les fichiers ou même les dossiers. Chaque nœud comporte également un ou plusieurs Datanode, auquel est assignée la tâche de gérer le stockage associé au nœud. Les blocs sont cartographiés par le Namenode pour les Datanodes.
En réalité, le Namenode et le Datanode sont des codes de programmation Java pouvant être lancés sur des machines commodity hardware. Ces machines fonctionnent généralement sous Linux OS ou GNU. Notons que l’intégralité du HDFS est basée sur le langage de programmation Java. Ainsi, le Namenode de chaque cluster Hadoop centralise toute la gestion des dossiers et des fichiers afin d’éviter toute ambiguité.
Le format suit un système de hiérarchisation de fichiers. Une application ou un utilisateur crée tout d’abord un dossier comportant des fichiers. La hiérarchisation des fichiers est identique aux autres systèmes de fichiers. Il est possible d’ajouter ou de supprimer un fichier et de déplacer les fichiers au sein d’un dossier ou même de les renommer.
La réplication de données est une partie essentielle du format HDFS. Comme le système est hébergé sur un commodity hardware, il est normal que les nœuds puissent tomber en panne sans crier gare. C’est pourquoi les données sont stockées de façon redondante, sous la forme d’une séquence de blocs. L’utilisateur peut facilement configurer la taille des blocs et le facteur de réplication. Les blocs de fichiers sont répliqués de façon à assurer la tolérance aux erreurs.
Quels sont les avantages de HDFS ?
HDFS présente plusieurs avantages évidents. Ce système de fichiers est distribué sur des centaines voire des milliers de serveurs, et chaque nœud stocke une partie du système fichier. Pour éviter le risque de perdre des données, chaque donnée est stockée à trois emplacements. Il est par ailleurs très efficace pour le traitement de flux de données.
Pour les grands ensembles de données, de l’ordre de plusieurs gigabytes ou terabytes, ce système de fichier distribué fonctionne également très bien. Il est donc très adapté au Big Data. Des dizaines de millions de fichiers peuvent être supportés sur une seule instance. Par ailleurs, cela assure la cohérence et l’intégrité des données pour éviter tout désagrément.
HDFS évite également la congestion de réseau en privilégiant le déplacement des opérations plutôt que le déplacement des données. Ainsi, les applications peuvent accéder aux données à l’endroit où elles sont entreposées. Dernier point fort : sa portabilité. Il peut fonctionner sur différents types de commodity hardwares sans aucun problème de compatibilité.
Plus qu’une base de données, ce système de fichier distribué se présente comme une Data Warehouse. Il est impossible de déployer un langage de requête sur HDFS, et les données sont accessibles par le biais de fonction de mapping et de réduction ( Hadoop MapReduce ). Les données adhèrent à un modèle de cohérence simple et robuste.

Pourquoi a-t-on besoin de HDFS ?
HDFS est essentiel pour le Big Data. Les données sont désormais trop nombreuses pour être stockées de façon centralisée, notamment à cause du coût et des contraintes de capacité de stockage. Cependant, grâce à la nature distribuée de ce dernier, il est possible de répartir les données sur différents serveurs afin de réaliser des économies.
La possibilité d’héberger ce système de fichier sur un Commodity Hardware est très pratique. En cas de besoin d’espace de stockage supplémentaire, il suffit simplement d’augmenter le nombre de serveurs ou de nœuds. HDFS se charge des nœuds à problème en stockant les mêmes données de façon redondantes à trois endroits différents. De plus, ce système est très efficace pour le traitement de flux de données. ce système est donc idéal pour le Big Data, dans un contexte où les données doivent être traitées en temps réel pour leur donner du sens.
HDFS remédie aux problèmes des précédents systèmes de gestion de données qui ne pouvaient prendre en charge les flux de données et les analyser en temps réel. L’échelonnage est très facile, et ce système peut donc s’adapter à tous les besoins sans une difficulté.
En tant que composant central de Apache Hadoop, il s’agit d’un outil dont la maîtrise peut s’avérer très rentable, car il cette compétence est très recherchée sur le marché du travail. Aux Etats-Unis, un développeur Hadoop Big Data peut toucher plus de 100 000 dollars par an.
- Partager l'article :




le titre indique » avantages et inconvénients du système de fichiers de Apache Hadoop » mais je ne vois écris que les avantages.
Je cherche plutot a comprendre les cotés positifs et négatifs de ce système de fichier. Quels sont les désavantages ?
Merci beaucoup de votre réponse 🙂