
Un cluster Hadoop est une grappe de serveurs permettant d’effectuer des analyses de données Big Data rapidement et efficacement, en répartissant la tâche entre les différents ordinateurs qui composent la grappe. Découvrez comment fonctionnent les clusters Hadoop, ainsi que leurs avantages et leurs inconvénients.
Un cluster Hadoop est un type spécial de cluster de calcul (grappe de serveurs) conçu spécifiquement pour stocker et analyser de grandes quantités de données non structurées au sein d’un environnement de calcul distribué. Le travail d’analyse de données est réparti entre les différents nœuds du cluster (serveurs). Ces clusters permettent de lancer le logiciel de traitement distribué open source Hadoop sur des ordinateurs low-cost. En général, l’une des machines du cluster est désignée en tant que NameNode, et une autre machine est désignée comme JobTracker. Ces deux machines sont les maîtres. Le reste des machines du cluster font à la fois office de DataNode et de TaskTracker. Elles sont les esclaves.
Cluster Hadoop : quelles sont les caractéristiques des grappes de serveurs ?
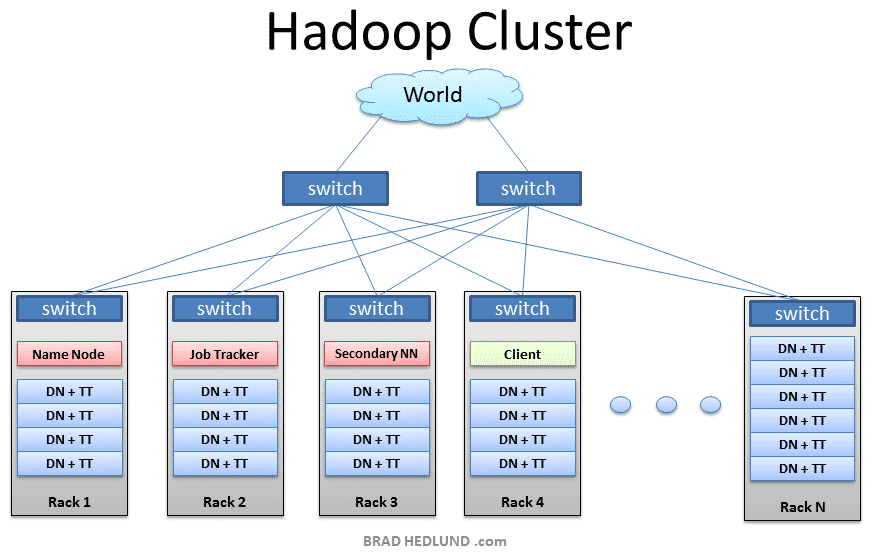
On fait souvent référence aux clusters Hadoop en tant que systèmes « Shared Nothing », car la seule chose que partagent entre eux les nœuds est le réseau qui les connecte. Les clusters Hadoop sont réputés pour permettre d’augmenter la vitesse des applications d’analyse de données. Ils sont également hautement scalables. Si la puissance de traitement d’un cluster est submergée par l’augmentation du volume de données, des nœuds additionnels peuvent être ajoutés pour augmenter la capacité du cluster.
Les clusters Hadoop sont également très résistants à l’échec, car chaque donnée est copiée sur d’autres nœuds du cluster, ce qui assure que les données ne seront pas perdues si l’un des nœuds tombe en panne. Depuis 2013, Facebook détient le record du plus large cluster Hadoop. Parmi les autres clusters d’envergure, on compte ceux de Google, Yahoo ou encore IBM.
Cluster Hadoop : avantages et inconvénients des grappes de serveurs

Les clusters Hadoop permettent de traiter de grandes quantités de données, et se révèlent donc très utiles pour le Big Data. Toutefois, ces grappes de serveurs ne sont pas adaptées à toutes les situations. En divisant les données et en assignant chaque partie à un nœud du cluster, Hadoop facilite l’analyse du Big Data. Les données n’ont pas besoin d’être uniformisées, car chaque pièce est prise en charge par un nœud du cluster. Il s’agit donc d’une solution idéale pour les données non structurées.
L’autre avantage est la scalabilité, qui permet de répondre à la problématique de l’augmentation permanente des Big Data. Le traitement parallèle proposé par Hadoop permet d’accélérer l’analyse, et donc de se rapprocher d’une analyse en temps réel, ce qui augmente grandement l’intérêt du Big Data. Si la puissance de traitement n’est pas suffisante, il est possible de l’augmenter graduellement pour répondre aux besoins. Enfin, le troisième avantage des clusters Hadoop est leur coût relativement bas, car Hadoop est un logiciel open source et nécessite pas d’ordinateur très puissant pour fonctionner.
Toutefois, les clusters Hadoop ne sont pas adaptés aux besoins de toutes les entreprises. Une entreprise qui ne dispose pas d’un grand nombre de données analysées ne bénéficiera pas du potentiel des clusters Hadoop. De même, pour les analyses de données qui ne peuvent pas être effectuées de façon parallèle, un cluster Hadoop n’est pas adapté. Le troisième problème des clusters Hadoop est que la courbe d’apprentissage est difficile pour développer, exploiter et maintenir un cluster. Sans expert Hadoop dans l’entreprise, il y a besoin de temps pour apprendre à effectuer les analyses de données sur un cluster. En somme, il incombe à chaque entreprise de s’assurer que ses besoins correspondent aux possibilités offertes par les clusters Hadoop.
En savoir plus sur Hadoop
- Hadoop – Tout savoir sur la principale plateforme Big Data
- Comparatif Hadoop : Top 7 des vendeurs commerciaux de distributions
- Partager l'article :



