MapReduce est un Framework de traitement de données en clusters. Composé des fonctions Map et Reduce, il permet de répartir les tâches de traitement de données entre différents ordinateurs, pour ensuite réduire les résultats en une seule synthèse. Découvrez ses origines, son fonctionnement, ses avantages, et les critiques émises à son égard.
Qu’est-ce que MapReduce ? Définition
MapReduce est un modèle de programmation créé par Google pour le traitement et la génération de larges ensembles de données sur des clusters d’ordinateurs. Il s’agit d’un composant central du Framework logiciel Apache Hadoop, qui permet le traitement résilient et distribué d’ensembles de données non structurées massifs sur des clusters d’ordinateurs, au sein desquels chaque nœud possède son propre espace de stockage. Concrètement, le framework propose deux fonctionnalités principales. Il répartit le labeur sur les différents nœuds du cluster (map), puis les organise et réduit les résultats fournis par chaque nœud en une seule réponse cohérente à une requête. Cela est rendu possible grâce à son système de fichiers distribués HDFS.
Quels sont les avantages de MapReduce ?

MapReduce fonctionne sur un large cluster de machines et est hautement scalable. Il peut être implémenté sous plusieurs formes grâce aux différents langages de programmation comme Java, C# et C++. Pour les développeurs débutants, le Framework est pratique car les routines de bibliothèques peuvent être utilisées pour créer des programmes parallèles sans se soucier des communications infra-cluster, de la surveillance de tâches ou de la gestion d’erreurs. Les programmeurs sans expérience dans le domaine des systèmes parallèles et distribués peuvent facilement utiliser des ressources de larges systèmes distribués.
Afin de distribuer les données entrées et de souder les résultats, il opère en parallèle sur des clusters massifs. La taille d’un cluster n’a pas d’impact sur le traitement des données. De fait, les tâches peuvent réparties sur n’importe quelle quantité de serveurs. C’est pourquoi MapReduce et Hadoop simplifient le développement de logiciels. Il est disponible dans plusieurs langages dont C, C++, Java, Ruby, Pearl et Python. Les programmeurs peuvent utiliser les bibliothèques MapReduce notamment basé sur Java 8 pour créer des tâches sans se soucier de la communication ou de la coordination entre les nœuds.
MapReduce pour les nuls ? Le principal avantage de ce framework est sa tolérance aux erreurs. Une tâche est transférée d’un nœud à l’autre, et si le nœud principal remarque qu’un nœud a été silencieux pendant un intervalle de temps plus long que prévu, le nœud principal assigne à nouveau la tâche à un autre nœud. Ceci crée une résilience et facilite le lancement de cette structure logicielle sur des serveurs peu coûteux.
MapReduce : comment fonctionne le framework ?
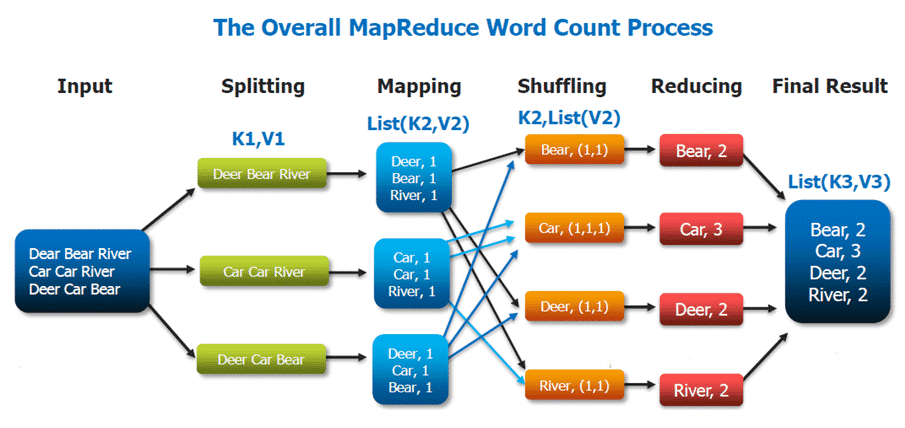
Le Framework se décompose en deux parties. La fonction Map permet aux différents points du cluster distribué de distribuer leur travail. La fonction Reduce permet de réduire la forme finale des résultats des clusters en un seul résultat. C’est la raison pour son nom rassemble les deux fonctionnalités. Ce Framework est également constitué de plusieurs composants. Job tracker est le nœud principal qui gère toutes les tâches et les ressources d’un cluster. Les TaskTrackers sont les agents déployés sur chaque machine d’un cluster pour lancer la map et réduire les tâches. JobHistoryServer est un composant permettant de suivre les tâches complétées, généralement déployé comme une fonction séparée ou avec JobTracker .
Le traitement des données a lieu sur les données stockées dans le système fichier ou au sein d’une base de données. Un ensemble de valeurs clés est entré et transformé en un autre ensemble de valeur clés produites par le framework. Le temps de lancement du système est prolongé par la partition des données d’entrée, la programmation de l’exécution du programme sur les ensembles de machines, la prise en charge des échecs de la machine et la gestion de la communication entre les machines.
Chaque jour, de nombreux programmes MapReduce sont effectués sur les clusters de Google. Les programmes sont automatiquement mis en parallèle et exécutés sur un large cluster de machines. MapReduce est utilisé pour la classification distribuée, le Web link-graph reversal, les statistiques d’accès au web, le clustering de documents, le machine learning et la traduction automatique de statistiques.
Par exemple, s’il est possible de compter manuellement le nombre de fois qu’un mot apparaît dans un roman, cela prend beaucoup de temps. Si l’on répartit cette tâche entre une vingtaine de personnes, les choses peuvent aller beaucoup plus vite. Chaque personne prend une page du roman et écrit le nombre de fois que le mot apparaît sur la page. Il s’agit de la partie Map de MapReduce. Si une personne s’en va, une autre prend sa place. Cet exemple illustre la tolérance aux erreurs de MapReduce. Lorsque toutes les pages sont traitées, les utilisateurs répartissent tous les mots dans 26 boîtes en fonction de la première lettre de chaque mot. Chaque utilisateur prend une boîte, et classe les mots par ordre alphabétique. Le nombre de pages avec le même mot est un exemple de la partie Reduce de MapReduce.
Aux origines du framework
À l’origine, il est un Framework développé pour l’indexage des pages web sur le moteur de recherche de Google. Il a permis à la firme de remplacer ses anciens algorithmes d’indexage. Toutefois, si ce terme désigne à l’origine la technologie propriétaire de Google, il est désormais employé de façon générique. Depuis 2014, Google n’utilise plus MapReduce comme son principal modèle de traitement du Big Data. Les bibliothèques MapReduce ont été écrites dans de nombreux langages de programmation différents, et l’implémentation d’Apache Hadoop est la plus populaire.
MapReduce : quelles sont les critiques à l’égard du framework
Plusieurs critiques sont émises à l’égard de MapReduce. Les computer scientists David DeWitt et Michael Stonebreaker, spécialisés dans les bases de données parallèles et les architectures shared-nothing, considèrent que MapReduce ne permet de résoudre qu’un faible nombre de problèmes. Selon eux, MapReduce n’est pas si novateur que le prétendent ses créateurs, et Teradata propose des fonctionnalités similaires depuis près de deux décennies.
Notons que Google a reçu un brevet très controversé pour un équivalent de cette architecture de programmation, car ce produit demeure très similaire à d’autres. Par exemple, les fonctionnalités Map et Reduce peuvent être implémentées facilement à des bases de données Oracle PL/SQL. Elle sont également prises en charge par des architectures de bases de données distribuées comme Clusterpoint XML ou MongoDB NoSQL.
De même, ces deux experts considèrent que le fait que MapReduce utilise des entrées de fichiers et ne prenne pas en charge suffisamment de schémas empêchent l’augmentation des performances proposées par la plupart des bases de données les plus communes. Notons toutefois que des projets comme Pig, Sawzall, Apache Hive, YSmart, HBase et BigTable permettent de remédier à ces problèmes. Par ailleurs, certains utilisent MapReduce et Spark en complément afin d’étendre les fonctionnalités. Des PDF sont disponibles sur la toile à ce sujet.
Cependant, Greg Jorgensen a réfuté ces critiques en affirmant que MapReduce n’a jamais été conçu comme une base de données, et que toutes les analyses formulées par DeWitt et Stonebraker sont totalement infondées. En réponse, DeWitt et Stonebraker ont publié un benchmark pour comparer les approches de MapReduce Hadoop et RDBMS sur différents problèmes spécifiques. Leur conclusion est que les bases de données relationnelles offrent de réels avantages pour de nombreux usages de données, notamment pour le traitement complexe, mais que le premier cité est plus facile à utiliser pour les tâches simples ou ponctuelles.
En savoir plus sur Hadoop Mapreduce
- Partager l'article :



