Le Speech-to-Text est une technologie de reconnaissance vocale qui permet de transformer un discours oral en texte de manière automatisée. Découvrez tout ce que vous devez savoir à ce sujet : définition complète, fonctionnement, cas d’usage, meilleurs logiciels…
La technologie Speech-to-Text permet de transformer n’importe quel contenu audio en texte écrit. Elle est aussi appelée reconnaissance vocale automatique, ou encore reconnaissance vocale par ordinateur.
Cette technologie fait partie du champ interdisciplinaire de la linguistique informatique. Elle repose à la fois sur des connaissances et des avancées des domaines de la linguistique, de la science informatique, et de l’ingénierie électrique.
À quoi sert le Speech-to-Text ?
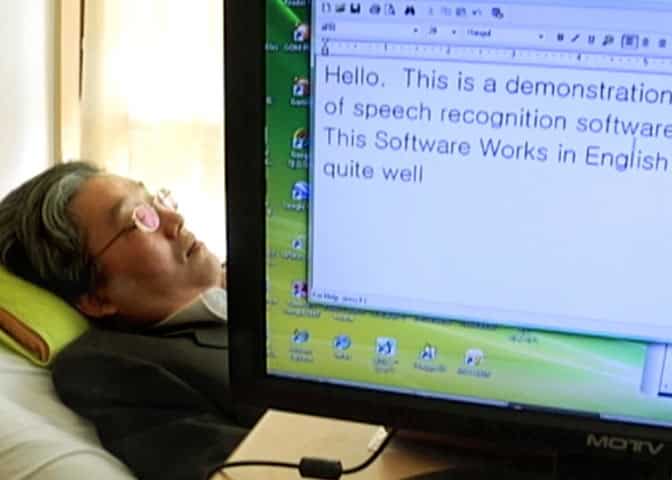
Les logiciels de Speech-to-Text peuvent se révéler très utiles pour les personnes qui ont besoin d’écrire une grande quantité de textes. La technologie leur permet de gagner du temps en leur évitant d’avoir à taper manuellement sur le clavier. Il leur suffit alors de dicter le texte et de laisser l’ordinateur se charger de le retranscrire à l’écrit.
Par ailleurs, cette technologie peut aussi être d’un grand secours aux personnes atteintes d’un handicap qui leur rend difficile ou impossible de taper sur un clavier.
De nos jours, de nombreux appareils électroniques tels que les ordinateurs et les smartphones embarquent nativement une technologie de Speech-to-Text dans leurs systèmes d’exploitation. Par exemple, les smartphones Android permettent de dicter oralement des SMS. Sur Microsoft Windows, les traitements de texte permettent de dicter du texte. De même, les moteurs de recherche comme Google permettent d’effectuer des recherches à l’oral.
Speech-to-Text : comment ça fonctionne ?
La plupart des logiciels de Speech-to-Text fonctionnent de la même façon. Dans un premier temps, le logiciel sépare les mots dictés par l’utilisateur en courts échantillons (samples). Ces échantillons sont ensuite associés à des phonèmes ou à des unités de prononciation.
Par la suite, les algorithmes complexes trient les résultats, afin de tenter de prédire quel mot ou quelle phrase a été prononcé par l’utilisateur. Au fil des dernières années, grâce aux progrès effectués dans le domaine du Deep Learning, du Big Data et de l’intelligence artificielle, la précision des technologies de Speech-to-Text s’est beaucoup améliorée.
Certains logiciels de Speech-to-Text nécessitent d’être « entraînés ». Pour ce faire, un utilisateur doit lire un texte ou des mots isolés afin que le système analyse sa voix et son intonation et s’entraîne à les reconnaître. Ceci permet d’augmenter la précision. D’autres systèmes fonctionnent indépendamment de l’utilisateur.
Speech-to-Text : quelles sont les principales solutions ?
Même si certains systèmes d’exploitation et autres applications proposent des fonctionnalités de Speech-to-Text, il existe aussi des applications spécialement dédiées à cette technologie. Parmi les exemples les plus connus, on peut citer Google Speech-to-Text et IBM Watson Speech-to-Text.
Google Speech-to-Text : le service Speech-to-Text de Google Cloud

Clood Speech-to-Text est l’un des nombreux services Cloud de Google. Il s’agit d’une API reposant sur la technologie de Machine Learning, permettant de convertir de l’audio en texte grâce à des modèles de réseaux de neurones artificiels.
Cette API reconnaît plus de 120 langages différents et leurs variantes. Elle est capable de traiter aussi bien le contenu audio préenregistré que l’audio streamé en temps réel. Cette technologie est notamment utilisée pour générer automatiquement les sous-titres des vidéos YouTube.
IBM Watson Speech-to-Text : l’intelligence artificielle au service du Speech-to-Text
https://www.youtube.com/watch?v=iY6h7d_Yx5Y
IBM Watson Speech-to-Text est le service de Speech-to-Text de Watson, l’intelligence artificielle d’IBM. Cette technologie est capable de traduire 7 langages différents en temps réel, même à partir d’un audio de faible qualité.
Le modèle utilisé peut être personnalisé pour améliorer la précision en fonction du contenu que l’utilisateur souhaite convertir. Ce service peut être utilisé pour de nombreux cas d’usage, tels que la transcription en temps réel ou l’analyse de milliers d’enregistrements audio en provenance d’un call center afin de procéder à l’analyse de données.
- Partager l'article :