
La plateforme de Data science Dataiku DSS propose aux équipes de professionnels des données de collaborer au sein d’un même environnement. Elle permet non seulement le traitement analytique des données, mais également le développement de nouvelles solutions. Découvrez tout ce que vous devez savoir sur Dataiku DSS.
D’abord, Dataiku DSS est une plateforme de développement intégrée, destinée aux professionnels des données. Elle permet de convertir efficacement les données en prédictions. Les équipes de spécialistes au sein d’une entreprise peuvent l’utiliser pour explorer, développer et produire leurs propres produits data plus efficacement.
A quoi consiste Dataiku DSS en 2026 ?
Dataiku est une plateforme de développement intégrée et bout en bout, conçue pour convertir efficacement les données brutes en prédictions actionnables. Ce logiciel se distingue fondamentalement par son approche collaborative, pensée pour démocratiser ce que l’entreprise appelle le « Everyday AI » ou l’intelligence artificielle au quotidien.

Véritable outil tout-en-un, il réunit les scientifiques de la donnée, les analystes métiers et les équipes d’exploitation au sein d’une seule et même interface. Le logiciel s’intègre par-dessus les infrastructures existantes des entreprises, qu’il s’agisse d’entrepôts de données SQL classiques ou de clusters de calcul distribué modernes. Ainsi, il confère un environnement agnostique qui permet la coexistence pacifique de tous les standards du Big Data et des différents langages de programmation.
À qui se destine Dataiku DSS ?
L’architecture de Dataiku est pensée pour satisfaire trois profils clés de l’entreprise. Elle sert les Data Analysts et les profils métiers, en se présentant comme une interface visuelle interactive où la souris remplace le code. Dataiku DSS leur permet de croiser des données, visualiser les résultats et obtenir des indicateurs stratégiques sur demande.
Pour les Data Scientists et les développeurs purs, la plateforme agit comme un puissant accélérateur. Elle facilite la préparation des jeux de données complexes et intègre nativement les meilleures bibliothèques d’apprentissage automatique comme Scikit-Learn ou H2O.
Enfin, pour les Data Ops, l’outil efface l’angoisse liée à la gestion de technologies fragmentées. Il coordonne le passage en production grâce à l’automatisation des flux de travail et à la surveillance continue des modèles prédictifs.
Les cas d’usage découlant de cette synergie sont innombrables. On constate que la plateforme est massivement déployée dans le secteur bancaire pour la détection de fraudes en temps réel. Le commerce de détail l’utilise pour l’optimisation des stocks, tandis que l’industrie pharmaceutique s’en sert pour faciliter la gestion des essais cliniques sous haute conformité.
Le cycle de vie de la donnée : de la connexion au Machine Learning
La vraie puissance de Dataiku repose sur sa capacité à gérer l’intégralité du cycle de la donnée. La première étape concerne la connectivité. Le logiciel se greffe aux infrastructures existantes sans jamais exiger le déplacement des données. Il sépare intelligemment le stockage de la puissance de calcul.
La plateforme est nativement compatible avec des dizaines de systèmes allant des bases SQL classiques aux environnements cloud modernes comme Amazon S3, en passant par les architectures NoSQL. Une fois connectée, la détection des formats est automatique.
Vient ensuite l’étape du nettoyage et de la préparation, souvent appelée Data Wrangling. Les utilisateurs accèdent à des dizaines de processeurs visuels pour nettoyer, filtrer et enrichir les données interactives sans écrire la moindre ligne de code. Des macros personnalisées en Python restent bien sûr disponibles pour les traitements spécifiques.
Pour l’exploration visuelle et le Data Mining, la plateforme propose des graphiques avancés générés par simple glisser-déposer. Les codeurs eux, peuvent approfondir l’analyse via des notebooks Jupyter interactifs intégrés nativement.
Concernant le Machine Learning, Dataiku propose une expérience guidée étape par étape. L’utilisateur peut entraîner ses modèles prédictifs, comparer leur efficacité via des validations croisées et recevoir un rapport visuel instantané expliquant quelles variables influencent le plus la prédiction. Cette transparence facilite grandement l’interprétation des modèles auprès des directions générales.
L’ère de l’IA générative : LLM Mesh et agents autonomes
Avec le déploiement successif de ses versions 13 et 14, Dataiku a franchi un cap technologique majeur en intégrant profondément l’intelligence artificielle générative. La grande révolution est surtout l’introduction du LLM Mesh.
Cette architecture intelligente agit comme un routeur sécurisé qui permet aux entreprises d’intégrer facilement les grands modèles de langage du marché dans leurs projets, tout en gardant un contrôle strict sur les coûts et la sécurité des données. Les entreprises peuvent ainsi développer des applications d’IA générative sans dépendre d’un seul fournisseur de modèle.
Cette avancée s’est accompagnée d’une flexibilité inédite pour la création d’agents d’IA autonomes. Les équipes peuvent désormais intégrer des outils Python tiers pour concevoir des flux de travail conversationnels et des assistants intelligents capables d’interagir avec les bases de données internes de l’entreprise.
L’interface utilisateur, repensée pour être encore plus intuitive, permet aux équipes moins techniques de s’approprier ces technologies de pointe grâce à des tableaux de bord hautement personnalisables.
Déploiement, MLOps et gouvernance en entreprise
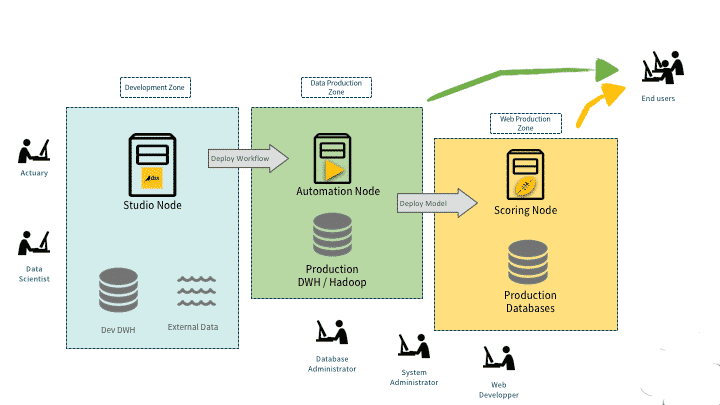
Le passage du développement à la production est le principal point de friction de la plupart des projets data. Dataiku résout ce problème en rendant cette transition presque transparente. En quelques clics, un modèle finalisé devient une API de prédiction capable de traiter des requêtes en temps réel. La plateforme gère nativement le versionnage des modèles, autorisant un retour en arrière immédiat en cas d’anomalie de production.
Cette industrialisation s’accompagne d’une gouvernance extrêmement stricte. Un catalogue centralisé documente chaque ensemble de données, chaque action et chaque algorithme déployé pour assurer une traçabilité parfaite.
Des tableaux de bord de surveillance dédiés informent les chefs de projet en continu sur l’état de santé des workflows. En cas de dérive prédictive d’un modèle d’intelligence artificielle, des alertes automatiques sont remontées. Et cela garantit que les décisions automatisées de l’entreprise restent fiables et pertinentes au fil du temps.
Tarification et accessibilité de la plateforme
Le modèle économique de Dataiku s’adapte à la taille et aux ambitions des entreprises. L’éditeur propose une architecture de licences basée sur le nombre d’utilisateurs et le niveau de fonctionnalités requises pour le déploiement de l’intelligence artificielle à grande échelle.
Pour obtenir une tarification précise, contactez directement les équipes commerciales de l’éditeur qui vont vous établir un devis sur mesure. Toutefois, pour les étudiants, les passionnés ou les petites équipes souhaitant découvrir l’écosystème, une version gratuite de découverte est mise à disposition. Et ce, bien que celle-ci soit logiquement amputée des fonctionnalités de collaboration avancée et d’industrialisation sécurisée.

FAQ – Tout savoir sur Dataiku DSS
C’est une plateforme unifiée d’intelligence artificielle et de Data Science qui permet aux entreprises de gérer l’intégralité de leurs projets de données. Elle centralise la préparation des bases de données brutes. Mais aussi l’entraînement des algorithmes d’apprentissage automatique et le déploiement sécurisé en production au sein d’une même interface collaborative.
Le logiciel a été conçu pour faire tomber les barrières entre les différents corps de métiers. Il s’adresse aux analystes commerciaux. Ces derniers profitent d’outils visuels sans code et aux data scientists qui peuvent intégrer leurs propres scripts Python ou R. Il sert aussi aux ingénieurs en charge du déploiement qui bénéficient d’une automatisation robuste de l’infrastructure logicielle.
La grande évolution récente de la plateforme tourne autour de la gestion sécurisée de l’intelligence artificielle générative. Avec l’introduction de son architecture LLM Mesh, Dataiku permet aux grandes organisations d’intégrer, de surveiller et de monétiser les grands modèles de langage de manière totalement sécurisée. Cette innovation s’accompagne d’une interface repensée pour faciliter la création d’agents autonomes par les équipes métiers.
Oui, l’éditeur propose effectivement une édition gratuite téléchargeable. Cette version de découverte s’avère idéale pour se familiariser avec l’interface visuelle ou pour mener à bien des projets individuels à petite échelle. Elle ne permet cependant pas d’accéder aux outils de gouvernance avancée et aux fonctions de déploiement en grappe nécessaires aux environnements de production des grandes entreprises.
- Partager l'article :



