
Pour profiter des bienfaits de l’analyse de données, il convient de connaître les algorithmes à utiliser. Voici les 5 algorithmes les plus utilisés pour le Big Data Analytics.
Le Big Data peut être très utile pour les entreprises. La plupart des organisations multinationales s’en remettent de nos jours à l’analyse de données pour aiguiller leurs décisions et ainsi stimuler leur croissance, augmenter leur chiffre d’affaires ou découvrir de nouvelles opportunités.
Toutefois, beaucoup d’entreprises qui souhaitent à leur tour exploiter le Big Data ne savent pas par où commencer. Si tel est votre cas, voici les 5 algorithmes Big Data les plus utilisés.
Analyse de données : régression linéaire
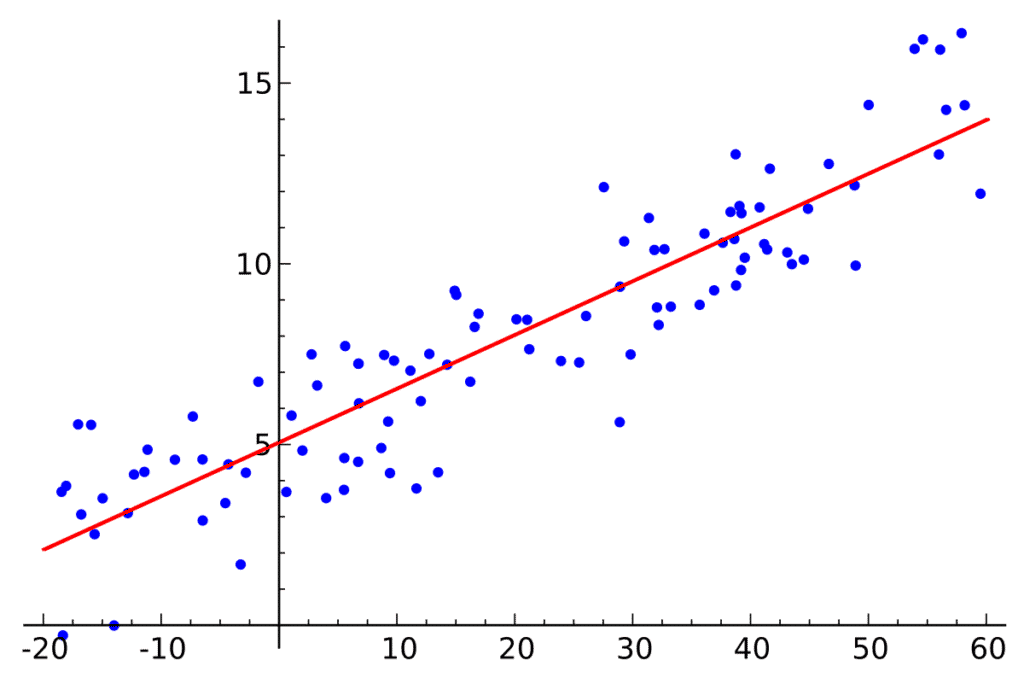
La régression linéaire est l’algorithme le plus basique et l’un des plus utilisés dans le domaine de l’analyse de données et du Machine Learning. Cet algorithme utilise la relation entre deux ensembles de mesures quantitatives continues.
Le premier ensemble est appelé » prédicteur » ou » variable indépendante « . Le second est appelé » réponse » ou » variable dépendante « . L’objectif de la régression linéaire est d’identifier la relation entre ces deux ensembles sous la forme d’une formule. Une fois la relation quantifiée, la variable dépendante peut être prédite pour n’importe quelle instance de la variable indépendante.
Analyse de données : régression logistique
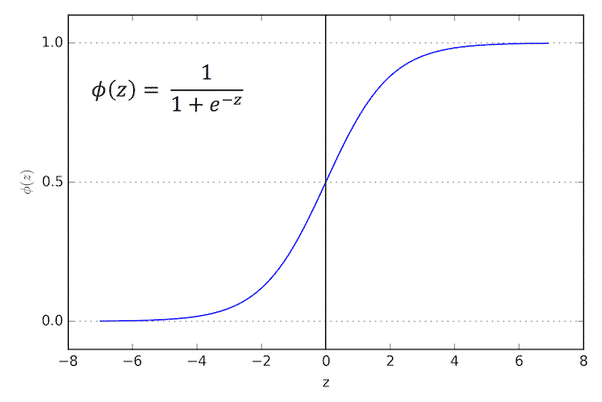
La régression logistique est similaire à la régression linéaire, mais elle est utilisée pour des problèmes de catégorisation plutôt que pour des prédictions quantitatives. L’objectif de cet algorithme est de déterminer si une instance d’une variable entre ou non dans une catégorie.
Ainsi, le résultat d’une régression logistique est une valeur comprise entre 0 et 1. Plus le résultat est proche de 1, plus la variable entre dans la catégorie. Au contraire, un résultat proche de 0 indique une probabilité que la variable n’entre pas dans la catégorie.
Analyse de données : arbres de classification et de régression

Les arbres de classification et de régression utilisent une décision pour catégoriser les données. Chaque décision est basée sur une question liée à l’une des variables entrantes. En fonction des réponses, l’instance de donnée est catégorisée. Cette succession de questions et de réponses et les divisions qui en découlent créent une structure en forme d’arbre.
Bien entendu, les arbres de classification peuvent vite devenir très larges et complexes. L’une des méthodes permettant de contrôler cette complexité est de supprimer certaines questions. Une variante des arbres de classification et de régression est celle des forêts aléatoires. Elle consiste à créer un cumul de petits arbres simples plutôt qu’un seul arbre avec de nombreuses branches. Chacun de ces petits arbres évalue une partie des données, puis les résultats sont assemblés pour créer une prédiction finale.
Analyse de données : méthode des k plus proches voisins
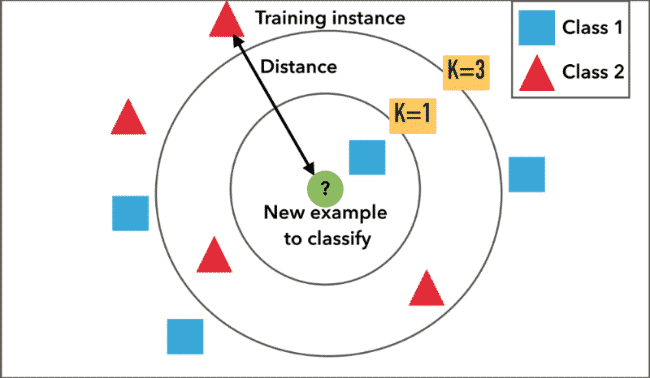
La méthode des k plus proches voisins est également un algorithme de classification. Dans un premier temps, on utilise un ensemble de données pour entraîner l’algorithme. Par la suite, la distance qui sépare les données d’entraînement des nouvelles données est évaluée pour catégoriser les nouvelles données.
En fonction de la taille de l’ensemble d’entraînement, cet algorithme peut nécessiter beaucoup de ressources de calcul. Il est toutefois souvent utilisé pour sa simplicité d’usage, sa facilité d’entrainement, et la facilité à interpréter les résultats.
Analyse de données : partitionnement en K-moyennes
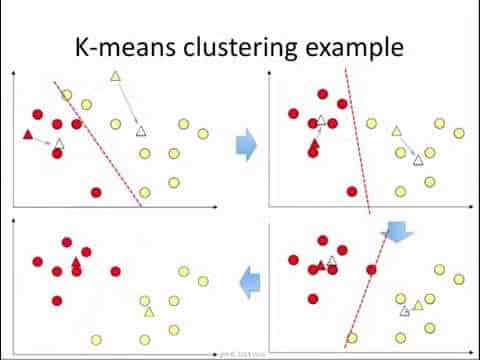
Le partitionnement en K-moyennes est une méthode qui consiste à créer des groupes d’attributs relatifs. Ces groupes sont appelés partitions. Une fois qu’ils sont créés, les autres instances peuvent être évaluées par rapport à eux afin de déterminer quelle catégorie leur correspond le mieux.
Cette technique est souvent utilisée dans le cadre de l’exploration de données. Les analystes définissent d’abord le nombre de partitions, puis les données sont réparties en fonction de leurs similitudes. Les partitions diffèrent des catégories, car il s’agit seulement d’instances liées de variables entrantes. Une fois identifiées et analysées, les partitions peuvent toutefois être converties en catégories. Cette méthode est souvent utilisée pour sa simplicité et sa vitesse.
Vous connaissez maintenant les algorithmes Big Data les plus utilisés. Chacun de ces algorithmes a ses avantages et ses inconvénients, et il est important de choisir le plus adapté en fonction de chaque situation.
- Partager l'article :



