
Machine Learning et Big Data : une combinaison puissante qui transforme l’analyse de données, les prédictions et les automatisations dans des domaines variés. Découvrez ses applications et enjeux.
Le Machine Learning est une technologie d’intelligence artificielle permettant aux ordinateurs d’apprendre sans avoir été programmés explicitement à cet effet. Pour apprendre et se développer, les ordinateurs ont toutefois besoin de données à analyser et sur lesquelles s’entraîner. De fait, le Big Data est l’essence du Machine Learning, et c’est la technologie qui permet d’exploiter pleinement le potentiel du Big Data. Découvrez pourquoi cette technique et le Big Data sont interdépendants.
Apprentissage automatique définition : qu’est ce que le Machine Learning ?
Le Machine Learning, ou apprentissage automatique, est une branche de l’intelligence artificielle permettant aux ordinateurs d’apprendre et d’évoluer sans être explicitement programmés. Grâce à l’analyse de grandes quantités de données, les ordinateurs identifient des patterns et réalisent des prédictions basées sur des algorithmes statistiques, la reconnaissance de motifs, et les analyses prédictives.
Depuis la création des premiers algorithmes comme le Perceptron à la fin des années 1950, cette discipline a considérablement évolué. Aujourd’hui, le Machine Learning est devenu une technologie clé dans le traitement des Big Data.
Pourquoi le Machine Learning et le Big Data sont-ils interdépendants ?
Le Big Data est indispensable au Machine Learning. En effet, les données volumineuses, variées et complexes fournissent la matière première nécessaire pour entraîner les algorithmes. Plus un système reçoit de données, plus il devient performant, améliorant ainsi la précision des prédictions et des analyses.
Contrairement aux outils analytiques traditionnels, le Machine Learning exploite efficacement la complexité du Big Data en :
- Identifiant des opportunités cachées sans intervention humaine directe.
- Segmentant les données.
- Analysant les relations entre différents jeux de données.

Les différents types d’algorithmes de Machine Learning
On distingue différents types d’algorithmes Machine Learning. Généralement, ils peuvent être répartis en deux catégories : supervisés et non supervisés.
Dans le cas de l’apprentissage supervisé, les données utilisées pour l’entraînement sont déjà » étiquetées « . Par conséquent, le modèle de Machine Learning sait déjà ce qu’elle doit chercher (motif, élément…) dans ces données. À la fin de l’apprentissage, le modèle ainsi entraîné sera capable de retrouver les mêmes éléments sur des données non étiquetées.
Parmi les algorithmes supervisés, on distingue les algorithmes de classification (prédictions non-numériques) et les algorithmes de régression (prédictions numérique). En fonction du problème à résoudre, on utilisera l’un de ces deux archétypes.
L’apprentissage non supervisé, au contraire, consiste à entraîner le modèle sur des données sans étiquettes. La machine parcourt les données sans aucun indice, et tente d’y découvrir des motifs ou des tendances récurrents. Cette approche est couramment utilisée dans certains domaines, comme la cybersécurité.
Parmi les modèles non-supervisés, on distingue les algorithmes de clustering (pour trouver des groupes d’objets similaires), d’association (pour trouver des liens entre des objets) et de réduction dimensionnelle (pour choisir ou extraire des caractéristiques).
Une troisième approche est celle de l’apprentissage par renforcement. Dans ce cas de figure, l’algorithme apprend en essayant encore et encore d’atteindre un objectif précis. Il pourra essayer toutes sortes de techniques pour y parvenir. Le modèle est récompensé s’il s’approche du but, ou pénalisé s’il échoue.
En tentant d’obtenir le plus de récompenses possible, il s’améliore progressivement. En guise d’exemple, on peut citer le programme AlphaGo qui a triomphé du champion du monde de jeu de Go. Ce programme a été entraîné par renforcement.

À quoi sert le Machine Learning ? Cas d’usage et applications
Le Machine Learning est omniprésent dans de nombreux services modernes, transformant des secteurs variés grâce à ses capacités d’analyse et de prédiction. Voici ses principales applications.
Recommandations personnalisées et moteurs de recherche
Les algorithmes de Machine Learning alimentent les moteurs de recommandations de Netflix, YouTube, Amazon ou Spotify. Ils analysent les données des utilisateurs pour suggérer des contenus adaptés à leurs goûts. De même, les moteurs de recherche comme Google et Baidu optimisent leurs résultats en s’appuyant sur ces technologies.
Réseaux sociaux et assistants vocaux
Les fils d’actualité de plateformes comme Facebook et Twitter utilisent le Machine Learning pour hiérarchiser les contenus selon les préférences des utilisateurs. Les assistants vocaux tels que Siri et Alexa s’appuient également sur cette technologie pour fournir des réponses pertinentes et précises.
Voitures autonomes et jeux vidéo
Les voitures autonomes utilisent le Machine Learning pour interpréter leur environnement. Bien que prometteur, ce domaine reste limité en milieu urbain, avec des défis importants à relever. Par ailleurs, l’IA excelle dans les jeux, surpassant les humains dans des compétitions comme le Go, les échecs ou Starcraft.

Les systèmes de Machine Learning excellent aussi dans le domaine des jeux. L’IA a d’ores et déjà surpassé l’humain au jeu de Go, aux échecs, au jeu de dames ou au shogi. Elle arrive aussi à triompher des meilleurs joueurs de jeux vidéo comme Starcraft ou Dota 2.

Analyse linguistique et médicale
On utilise aussi le Machine Learning pour la traduction linguistique automatique, et pour la conversion du discours oral à l’écran (speech-to-text). Un autre cas d’usage est l’analyse de sentiment sur les réseaux sociaux, reposant également sur le traitement naturel du langage (NLP).

Machine Learning et radiographies médicales
Le Machine Learning est aussi utilisé pour l’analyse et la classification automatique des images de radiographies médicales. L’IA se révèle très performante dans ce domaine, parfois même plus que les experts humains pour détecter des anomalies ou des maladies. Toutefois, elle ne peut pas encore remplacer totalement les spécialistes compte tenu des enjeux.
Les biais dans le recrutement automatisé
Plusieurs entreprises ont tenté d’exploiter le Machine Learning pour passer en revue les CV des candidats de manière automatique. Toutefois, les biais des données d’entraînement mènent à une discrimination systématisée à l’égard des femmes ou des minorités.
En effet, les systèmes de Machine Learning tendent à favoriser les candidats dont le profil est similaire aux candidats actuels. Ils tendent donc à perpétrer et à amplifier les discriminations déjà existantes dans le monde de l’entreprise.
C’est un réel problème, et Amazon a par exemple préféré cesser ses expériences dans ce domaine. De nombreuses entreprises tentent de lutter contre les biais dans les données d’entraînement de l’IA, telles que Microsoft, IBM ou Google.
Les controverses autour de la reconnaissance faciale
La technologie controversée de reconnaissance faciale repose elle aussi sur le Machine Learning. Toutefois, là encore, les biais dans les données d’entrainement posent un grave problème.
Ces systèmes sont principalement entraînés sur des photos d’hommes blancs, et leur fiabilité se révèle donc bien inférieure pour les femmes et les personnes de couleur. Ceci peut mener à des erreurs aux conséquences terribles. Des innocents ont par exemple été confondus avec des criminels et arrêtés à tort…

Machine Learning et Big Data : pourquoi utiliser le Machine Learning avec le Big Data ?
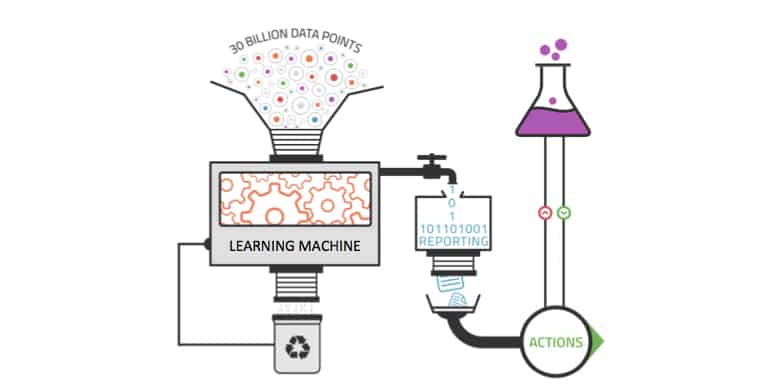
Les outils analytiques traditionnels ne sont pas suffisamment performants pour exploiter pleinement la valeur du Big Data. Le volume de données est trop vaste pour permettre des analyses compréhensives. Les corrélations et relations entre ces données sont également trop nombreuses pour que les analystes puissent tester toutes les hypothèses et en dégager une valeur.
Les méthodes analytiques basiques sont utilisées par les outils de business intelligence et de reporting pour le rapport des sommes, pour faire les comptes et pour effectuer des requêtes SQL. Les traitements analytiques en ligne sont une extension systématisée de ces outils analytiques basiques qui nécessitent l’intervention d’un humain pour spécifier ce qui doit être calculé.
Comment ça marche ?
Le Machine Learning est idéal pour exploiter les opportunités cachées du Big Data, les algorithmes d’apprentissage automatique peuvent être appliqués à chaque élément de l’opération Big Data, notamment le Segmentation des données, Analyse des données et la Simulation. Cette technologie permet d’extraire de la valeur en provenance de sources de données massives et variées sans avoir besoin de compter sur un humain. Elle est dirigée par les données, et convient à la complexité des immenses sources de données du Big Data.
Contrairement aux outils analytiques traditionnels, il peut également être appliqué aux ensembles de données croissants. Plus les données injectées à un système Machine Learning sont nombreuses, plus ce système peut apprendre et appliquer les résultats à des insights de qualité supérieure. Le Machine Learning permet ainsi de découvrir les patterns enfouis dans les données avec plus d’efficacité que l’intelligence humaine.

La fusion de l’apprentissage automatique et du Big Data est une chaîne perpétuelle. Les algorithmes créés à des fins précises sont contrôlés et perfectionnés au fil du temps à mesure que les données entrent dans le système et en sortent.

Des cours de Machine Learning sont disponibles sur le Web. Ils permettent notamment de débuter l’apprentissage automatique à partir du langage informatique Python. Ce dernier, assez simple à apprendre, autorise donc les néophytes à tester des applications utilisant cette technique avec Python. De même, les open classroom permettent de découvrir gratuitement le fonctionnement de cette technique de traitement des données.
Machine Learning et Big Data : pourquoi le Machine Learning n’est rien sans Big Data
Sans le Big Data, le Machine Learning et l’intelligence artificielle ne seraient rien. Les données permettent aux algorithmes de détecter des motifs, de s’améliorer et d’automatiser des tâches complexes. Sans le Big Data, l’intelligence artificielle ne pourrait atteindre son plein potentiel. Aujourd’hui, les avancées technologiques facilitent l’accès à des données massives en temps réel, rendant les systèmes plus agiles et performants.

Des entreprises comme MetLife exploitent cette technologie pour optimiser leurs opérations, notamment grâce à la reconnaissance vocale et à l’analyse de données non structurées. Les objets connectés, tels que les thermostats intelligents, illustrent également le potentiel du Machine Learning dans la gestion énergétique, adaptant les paramètres domestiques aux habitudes des utilisateurs.
En combinant Big Data et Machine Learning, les entreprises de divers secteurs améliorent leurs services, augmentent leur efficacité et se positionnent pour répondre aux besoins futurs.
Le Deep Learning, un sous-domaine du Machine Learning

Le Deep Learning, une sous-catégorie du Machine Learning, repose sur des réseau neuronal inspiré des systèmes cérébraux . Il est conçu pour traiter des données complexes et non structurées, comme des images, des sons ou des textes, en automatisant des tâches avec une précision impressionnante.
L’une de ses applications phares est la reconnaissance visuelle, utilisée pour identifier des individus ou analyser des expressions faciales. Il est également employé dans la reconnaissance vocale, permettant de comprendre le ton, la voix, et les contextes de conversation. Ces fonctionnalités trouvent des applications dans divers secteurs, tels que la surveillance, le commerce ou les interactions humaines.
Le Deep Learning utilise différentes méthodes d’apprentissage : supervisé, non supervisé, semi-supervisé, par transfert ou par renforcement, selon les besoins et les objectifs des projets. Cependant, cette technologie est gourmande en ressources. Elle nécessite :
- Un grand volume de données pour entraîner les modèles avec précision.
- Une puissance de calcul importante, mobilisant souvent des GPU ou des TPU.
Bien que son implémentation soit complexe et coûteuse, le Deep Learning reste une pierre angulaire de l’intelligence artificielle, ouvrant des perspectives dans des domaines variés, de la santé à la sécurité, en passant par le divertissement.
Les réseaux de neurones
Les réseaux de neurones artificiels s’inspirent de l’architecture du cortex visuel biologique. Le Deep Learning consiste en un ensemble de techniques permettant à un réseau de neurones d’apprendre grâce à un grand nombre de couches permettant d’identifier des caractéristiques.
De nombreuses couches sont dissimulées entre l’entrée et la sortie du réseau. Chacune est constituée de neurones artificiels. Les données sont traitées par chaque couche es=t les résultats sont transmis à la suivante.
Plus un réseau de neurones comprend d’épaisseurs, plus le nombre de calculs nécessaire pour l’entraîner sur un CPU augmente. On utilise aussi des GPU, des TPU et des FPGA en guise d’accélérateurs hardware.

Machine Learning et Big Data : les analyses prédictives donnent du sens au Big Data

Les analyses prédictives utilisent des données, des algorithmes statistiques et des techniques de Machine Learning pour anticiper les tendances et les résultats financiers, aidant ainsi les entreprises à prendre des décisions stratégiques éclairées. Elles intègrent diverses disciplines comme le data mining, le modelling prédictif, et le Machine Learning. Cela permet, par exemple, d’anticiper les réactions des consommateurs ou les conséquences d’une décision.
Ces analyses transforment de vastes ensembles de données en insights exploitables, optimisant ainsi l’expérience client et la performance des entreprises. Avec l’essor des données, des outils analytiques avancés comme Salesforce Einstein, et une puissance informatique accrue, les analyses prédictives sont devenues accessibles à un grand nombre d’entreprises.
Une étude de Bluewolf révèle que 75 % des entreprises investissant dans ces technologies en tirent des bénéfices concrets, et 81 % des utilisateurs de Salesforce les considèrent comme essentielles pour leur stratégie de ventes. En automatisant les décisions, elles améliorent la rentabilité et la productivité.
À un niveau avancé, l’intelligence artificielle et les systèmes cognitifs ajoutent des capacités telles que la compréhension des données non structurées, le raisonnement, et l’interaction naturelle avec les humains. En clair, cela place les analyses prédictives au sommet des solutions d’analyse de données modernes.
Machine Learning et Big Data : l’apprentissage automatique au service du Data Management

Face à l’augmentation massive du volume de données stockées par les entreprises, ces dernières doivent faire face à de nouveaux défis.
Parmi les principaux challenges liés au Big Data, on dénombre la compréhension du Dark Data, la rétention de données, l’intégration de données pour de meilleurs résultats analytiques, et l’accessibilité aux données. Le Machine Learning peut s’avérer très utile pour relever ces différents défis.
Machine Learning au service du Dark Data
Toutes les entreprises accumulent au fil du temps de grandes quantités de données qui demeurent inutilisées. Il s’agit des dark data. Grâce au Machine Learning et aux différents algorithmes, il est possible de faire le tri parmi ces différents types de données stockées sur les serveurs. Par la suite, un humain qualifié peut :
- passer en revue le schéma de classification suggéré par l’intelligence artificielle,
- y apporter les changements nécessaires,
- et le mettre en place.
Pour la rétention de données, cette pratique peut également s’avérer efficace. L’intelligence artificielle peut identifier les données qui ne sont pas utilisées et suggérer lesquelles peuvent être supprimées. Même si les algorithmes n’ont pas la même capacité de discernement que les être humains, le Machine Learning permet de faire un premier tri dans les données. Ainsi, les employés économisent un temps précieux avant de procéder à la suppression définitive des données obsolètes.
Machine Learning et l’intégration de données
Pour tenter de déterminer le type de données qu’ils doivent agréger pour leurs requêtes, les analystes créent généralement un répertoire dans lequel ils placent différents types de données en provenance de sources variées pour créer un bassin de données analytique.
Pour ce faire, il est nécessaire de développer des méthodes d’intégration pour accéder aux différentes sources de données en provenance desquelles ils extraient les données. Cette technique peut faciliter le processus en créant des mappings entre les sources de données et le répertoire. Ceci permet de réduire le temps d’intégration et d’agrégation.
Enfin, l’apprentissage des données permet d’organiser le stockage de données pour un meilleur accès. Au cours des cinq dernières années, les vendeurs de solutions de stockage de données ont mis leurs efforts dans l’automatisation de la gestion de stockage. Grâce à la réduction de prix du SSD, ces avancées technologiques permettent aux départements informatiques d’utiliser des moteurs de stockage intelligents.
Basées sur le machine Learning, elles permettent de voir quels types de données sont utilisés le plus souvent et lesquels ne sont pratiquement jamais utilisés. L’automatisation peut être utilisée pour stocker les données en fonction des algorithmes. Ainsi, l’optimisation n’a pas besoin d’être effectuée manuellement.
Une forme pauvre de l’IA ?
Certaines voix s’élève au sein des entreprises afin de rappeler que l’humanité est au début du développement de l’intelligence artificielle. Selon Alex Danvy, Evengéliste technique chez Microsoft France, le machine learning aujourd’hui est une forme simple d’IA. Les algorithmes ne sont pas encore capables d’accomplir les tâches aussi complexes que celles confiées à Skynet, le réseau informatique fictif du film Terminator.
Qu’ils traitent des images, des sons, du texte, les algorithmes réalisent des tâches simples. Ce n’est qu’en interconnectant les aglorithmes que l’on arrive à créer des systèmes plus intelligents. C’est de cette manière que sont pensées les voitures autonomes. Malheureusement, les acteurs de l’intelligence artificielle créent leurs solutions « dans leur coin », explique Alex Danvy. Selon lui, cela n’empêche pas l’émergence de solutions efficaces basés sur des algorithmes de machine learning « simples ».
FAQ sur le Machine Learning
Le Machine Learning (apprentissage automatique) est une branche de l’intelligence artificielle. Il permet aux systèmes d’apprendre et de s’améliorer à partir des données sans être explicitement programmés. Contrairement à l’IA traditionnelle qui fonctionne avec des règles prédéfinies, le Machine Learning utilise des algorithmes.
Le Big Data fournit la matière première essentielle au Machine Learning: d’immenses volumes de données diverses. Le Machine Learning, quant à lui, exploite ces données pour entraîner des modèles performants. Plus les données sont nombreuses et variées, plus les modèles peuvent identifier des corrélations complexes et faire des prédictions précises. Le Big Data apporte la quantité, tandis que les algorithmes de Machine Learning apportent l’intelligence analytique. Les technologies de traitement distribué comme Hadoop et Spark permettent d’analyser ces volumes de données massifs.
Les principaux défis éthiques concernent la confidentialité des données, les biais algorithmiques et la transparence. La collecte massive de données soulève des questions sur le consentement et la vie privée. Les algorithmes peuvent perpétuer ou amplifier des biais présents dans les données d’entraînement. Le caractère « boîte noire » de certains modèles complexes limite leur explicabilité.
- Partager l'article :




Merci pour cette page mieux documentée que les autres. Ce qui est complexe dans l’IA, c’est de l’expliquer de façon générique, ça donne une vision mono-culturelle de cette spécialité, comme si le terme IA suffisait à résoudre tout ce qui va au delà des automatismes.
Dans la réalité, on ne traite qu’un cas à la fois et on filtre les résultats avec plusieurs techniques dont certaines sont assez « simples » (SQL, heuristiques pleines de IF ou matrices)
Je vais lire votre article sur Tensorflow pour voir comment vous le définissez (vous pouvez sans doute récupérer quelques liens sur ma page)
Peu importe comment on les appelle – Intelligence Artificielle ou Machine Learning ; c’est la donnée qui est le fondement de ces technologies en constante évolution.
MATRIX !!!!! ils sont fous
Cher rédacteur,
Pourriez vous réaliser un machine learning du Français à votre traitement de texte s’il vous plaît ?
Je ne me suis pas « planté » à la première erreur d’écriture, en revanche je n’ai pas atteint la dernière ligne, car après surprise, et indulgence, j’ai ressenti les premiers patterns de la lassitude.
Une question me vient :
La machine et l’homme, dans leurs interactions successives, sont ils capables de s’appauvrir réciproquement ?
Merci tout de même pour le fond de l’article et pour les perspectives intéressantes évoquées.
Merci pour cette page car,elle était brève ,enrichissante et éveillante sur ce qu’on ignores
Bjr. Extraordinaire ce qu’on peut faire en machine learning. J’aimerais me former, trouver du travail dans ce domaine afin de me perfectionner. Merci de bien vouloir m’orienter, m’aider.