
Apache Kafka est une plateforme de streaming distribuée gérée par la fondation Apache. Découvrez tout ce que vous devez savoir sur cet outil majeur du Big Data : ses origines, son fonctionnement, ses avantages, ses cas d’usage ainsi que les raisons de sa popularité croissante.
À l’origine, Apache Kafka était un système de messagerie distribué. Au fil du temps, cet outil a beaucoup évolué. Il s’agit aujourd’hui d’une plateforme centralisée pour le stockage et l’échange en temps réel de toutes les données émises par les entreprises qui l’utilisent. De nombreuses firmes l’ont adopté, à tel point que Kafka est aujourd’hui considéré comme une plateforme standard pour les pipelines de traitement de données.
Apache Kafka : aux origines de la plateforme
Tout commence en 2009. Une équipe de LinkedIn est chargée de prendre en charge l’adoption Hadoop. Malheureusement, elle se trouve confrontée à des problèmes d’intégration des données en provenance des différents systèmes déjà utilisés par l’entreprise.
L’équipe entreprend alors de créer un outil capable de centraliser les flux de données en provenance des différents systèmes de l’entreprise. Un système distribué capable de monter en charge (scalable) horizontalement, et de supporter des débits très importants pour la publication ou la lecture de données.
Ce produit devait aussi supporter la consommation d’un flux de données par des consommateurs multiples, d’assurer le découplage des systèmes producteurs et consommateur de données, et de permettre la consommation des messages en temps réel et en mode batch.
Plutôt que de s’en remettre aux outils traditionnels de brokers de messages d’entreprise comme RabbitMQ et ActiveMQ, LinkedIn a choisi de créer son propre outil avec Scala. C’est ainsi qu’est né Apache Kafka un système de messagerie distribué en mode publish-subscribe, capable de monter facilement en charge, de supporter des débits de données très importants et d’assurer la persistance des données qu’il reçoit.
Apache Kafka : comment fonctionne le système ?
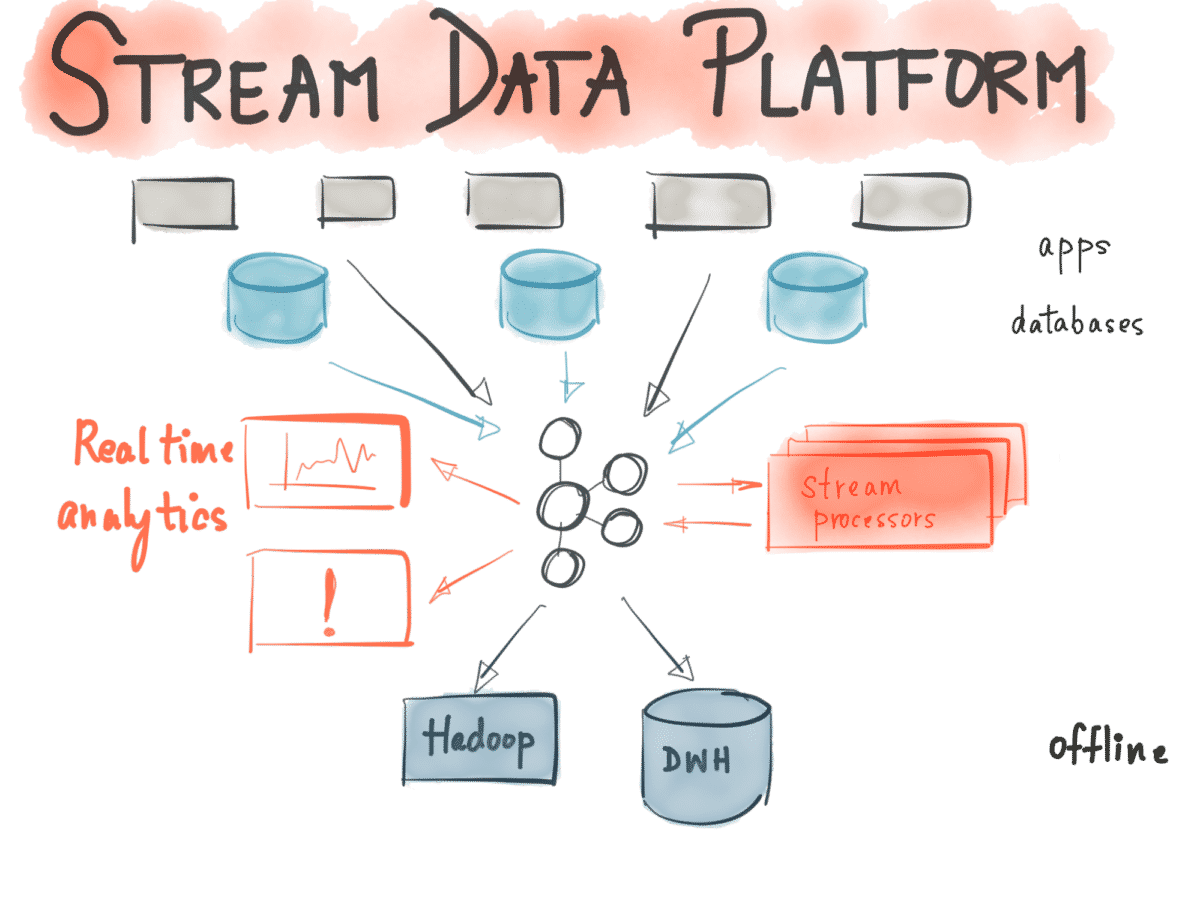
Les données reçues par Apache Kafka sont conservées au sein de topic. Chaque topic correspond à une catégorie de données. Les systèmes qui publient des données dans les topics Kafka sont des Producers. Les systèmes qui lisent les données des topics sont quant à eux des Consumers.
Les Producers envoient les messages (constitués d’une clé optionnelle et d’une valeur) vers un topic Kafka sous forme d’un tableau de bytes. Ainsi, les messages sont transmis et persistés dans un format arbitraire comme JSON et Avro. Les messages qui possèdent une même clé sont automatiquement envoyés vers la même partition d’un topic.
Le système repose sur le log, une structure de données abstraites. Le log se présente comme un array de messages, au sein duquel les données sont ordonnées en fonction du temps de réception des messages. Chaque partition d’un topic se comporte comme un commit log.
Les différentes étapes du système sont distribuées. Plusieurs Producers peuvent émettre des données vers un même topic, et un Consumer d’un topic peut lui aussi être un système distribué comme Hadoop ou Spark. Les données d’un topic sont partitionnées et répliquées dans les différents brokers du cluster dédié, ce qui permet d’assurer une tolérance à la panne et un débit d’écriture et de lecture très important.
Plus qu’un simple système de messages, il est souvent considéré comme un système de commit logs distribué. La persistance des messages dans commit log permet à plusieurs Consumers d’extraire les messages d’un même topic à leur propre rythme. Ainsi, un même topic peut être utilisé comme source de données d’un système batch ou d’un système de stream processing.
Pourquoi est-il si performant ? Quels sont ses avantages ?
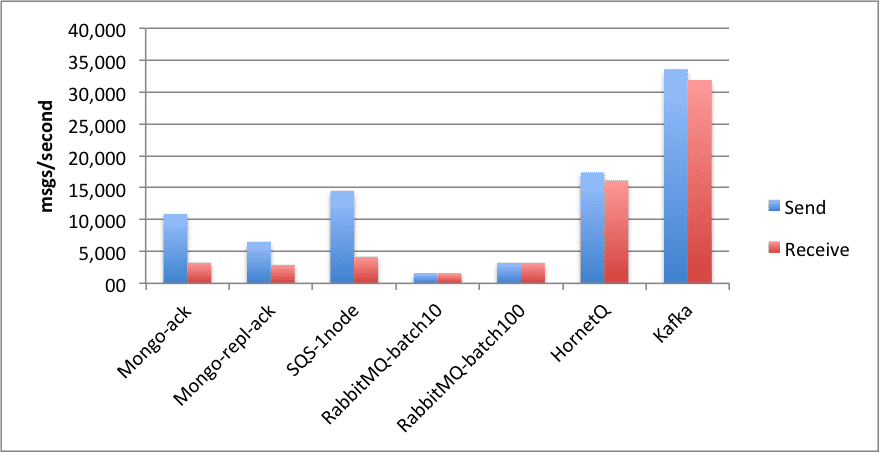
Même s’il persiste les messages sur disque, Apache Kafka propose des performances impressionnantes. Plusieurs raisons à cela. Tout d’abord, il fait en sorte, quand c’est possible, que les petites opérations d’écriture provoquent une seule écriture sur disque. C’est ce qu’on appelle le batching.
En outre, la plupart des opérations sur disques sont séquentielles, ce qui garantit d’excellentes performances de débit de lecture et d’écriture par rapport à des lectures/écritures aléatoires en mémoire. Par ailleurs, les systèmes d’exploitation récents utilisent la mémoire disponible en guise de cache des opérations sur disque, ce qui rend les écritures aléatoires sur disque plus rapide.
Apache Kafka évite de conserver un cache en mémoire des données, ce qui lui permet de s’affranchir de l’overhead en mémoire des objets dans la JVM et de la gestion du Garbage Collector. De plus, la plateforme s’appuie sur un mécanisme en zero copy pour envoyer des messages aux consommateurs. Les données passent directement de la tête de lecture sur disque à la socket réseau, permettant là encore d’augmenter les performances.
Apache Kafka : qui utilise la plateforme et pourquoi ? Quels sont les cas d’usage ?

La plateforme est utilisée par de nombreuses entreprises au sein de pipelines de traitements de données. La plateforme est utilisée pour l’agrégation de logs, le stream processing, le monitoring, le tracking d’activité, les bus de messages, la collecte Big Data et l’analyse en temps réel, le CEP, l’ingestion de données dans Spark ou Hadoop, le CQRS, ou encore l’event sourcing. De plus en plus d’entreprises l’utilisent dans leur Data Center.
Beaucoup de grandes entreprises utilisent Apache Kafka. LinkedIn, son créateur, l’utilise pour le tracking de données d’activité. Twitter l’utilise en guise de composant de Storm comme infrastructure de stream processing. Square utilise Kafka comme bus pour transférer tous les événements système vers ses différents Data Centers et pour implémenter des systèmes d’alerte Esper-like/CEP.
Parmi les autres utilisateurs renommés d’Apache Kafka, on compte Spotify, Uber, Tumblr, Goldman Sachs, PayPal, Box, Cisco, CloudFlare, et Netflix. Au total, plus d’un tiers des entreprises du Fortune 500 l’utilise. C’est le cas des 10 premières entreprises de l’industrie du tourisme, sept des 10 plus grandes banques, 8 des dix plus grandes compagnies d’assurance, neuf des dix plus grandes entreprises de télécommunication.
En outre, LinkedIn, Microsoft et Netflix traitent plus de 300 milliards de messages par jour avec Apache Kafka, avec des pics à 4,5 millions de messages par seconde. Microsoft utilise aussi un cluster de plus de 1000 brokers Kafka. Ce cluster peut ingérer jusqu’à un million de messages par seconde et délivre jusqu’à 5 millions de messages par seconde. La popularité de Kafka est liée à sa facilité de déploiement et d’utilisation, mais surtout à ses performances impressionnantes.
- Partager l'article :




Je crois qu’il y a une erreur de traduction sur les trillions : les trillions anglo saxons, c’est des milliers de milliards (10^12). Les trillions français, ils viennent dans la série millions (10^6), milliards (10^9), billions (10^12), billiards (10^15), trillions (10^18).
à 5 millions de messages par seconde, il est impossible d’arriver au trillion dans une journée
Effectivement, merci !