
Le stockage de données dans l'ADN est une technologie en passe de révolutionner le Data Storage dans les années à venir en remplaçant les supports de stockage actuels tels que les disques durs ou même le Cloud Computing. Découvrez tout ce que vous devez savoir à sujet.
Avec l'essor de l'internet des objets, des réseaux sociaux, des véhicules autonomes ou encore du e-commerce, le volume de données générées par l'humanité est en pleine explosion. Selon IDC, le volume de données mondial atteindra 175 zettabytes en 2025 contre 33 zettabytes en 2018.
Face à cette augmentation massive, il est urgent et nécessaire de trouver de nouvelles solutions pour le stockage de ces données. Pour cause, les Data Centers sur lesquels ont stocke actuellement les données via le Cloud consomme énormément d'énergie et ont une empreinte carbone massive. Rien qu'aux États-Unis, les centres de données consomment plusieurs milliards de kilowatts d'électricité par an. Ils représentent 2% de la consommation d'énergie totale aux États-Unis.
Il est donc plus que temps de trouver une alternative. Pour éviter une crise du Data Storage, plusieurs chercheurs et entreprises misent sur le stockage de données dans l'ADN…
Stockage ADN : qu'est-ce que c'est ?
Pour rappel, l'acronyme ADN désigne l'acide désoxyribonucléique. Il s'agit d'une substance que l'on retrouve dans les cellules de tous les êtres vivants, et dont le rôle est de contenir les informations génétiques. L'ADN contient des dizaines de milliers de gènes visant à déterminer chacune de nos caractéristiques, de notre apparence physique à notre personnalité.
Ainsi, l'ADN est l'équivalent naturel des disques durs et autres supports de stockage. C'est la raison pour laquelle plusieurs chercheurs envisagent d'y stocker des données numériques.

Comment fonctionne le stockage ADN ?
Le stockage ADN consiste à encoder des données binaires dans l'ADN. Pour ce faire, les bits individuels (chiffres binaires) sont convertis de 1 et 0 vers les lettres A, C, G et T. Ces lettres représentent les quatre principaux composants de l'ADN : l'adénine, la cytosine, la guanine et la thymine.
Le médium de stockage physique est une molécule d'ADN synthétisée contenant ces quatre composants dans une séquence correspondant à l'ordre des bits dans le fichier numérique. Pour récupérer ces données, la séquence A, C, G et T représentée dans la molécule d'ADN est à nouveau décodée sous la forme de la séquence originale de bits 1 et 0.
Les avantages et les inconvénients
L'un des principaux avantages de l'ADN pour le stockage de données est sa grande densité. Selon les experts, un système de stockage basé sur l'ADN pourrait stocker un milliard de fois plus de données que les appareils électroniques traditionnels de dimensions similaires. Dans un gramme d'ADN, il est possible de stocker 215 petabytes de données. Il serait donc possible de stocker toutes les données créées par les humains dans une seule pièce.

De plus, l'ADN peut théoriquement conserver les données en parfait état pendant une durée extrêmement longue. Dans les conditions idéales, on estime que l'ADN pourrait toujours être déchiffré après plusieurs millions d'années grâce aux » gènes de longévité « . En outre, l'ADN peut résister aux conditions climatiques les plus extrêmes.
En revanche, selon les experts du World Economic Forum, plusieurs obstacles doivent être surmontés avant que les systèmes de stockage ADN puissent réellement rivaliser avec les systèmes électroniques traditionnels.
À l'heure actuelle, les principaux points faibles sont un coût élevé et des temps de traitement qui peuvent s'avérer extrêmement longs. Cependant, selon le Dr Nick Goldman de l'EMBL, d'ici le milieu des années 2020, le coût pourrait diminuer suffisamment pour que cette technologie devienne viable à grande échelle.
Microsoft et le stockage ADN

Parmi les entreprises et institutions qui travaillent sur le stockage de données dans l'ADN, Microsoft est l'une des plus influentes. En avril 2019, la firme de Redmond a annoncé avoir développé le premier système de stockage ADN entièrement automatisé.
Selon l'article publié par les chercheurs de Microsoft et de l'Université de Washington dans le journal Nature Scientific Reports, les équipes sont parvenues à encoder le mot » hello » dans des molécules d'ADN créées en laboratoire avant de le convertir à nouveau sous forme de données numériques.
Les chercheurs ont également réussi à démontrer que l'ADN peut permettre de stocker des photographies, des documents textuels, ou même des fichiers audio et vidéo et de les récupérer en parfait état.
Pour l'heure, le processus s'avère toutefois long et coûteux. Il a fallu 21 heures pour écrire, stocker et lire le fichier de 5 bytes contenant le mot » hello « . De plus, l'appareil de stockage ADN développé par Microsoft coûte environ 10 000 dollars à produire.
Cependant, en éliminant les capteurs et les actionneurs les plus coûteux, le prix pourrait tomber à 3000 ou 4000 dollars. Sur le long terme, l'objectif de l'entreprise est de continuer à développer son système de stockage ADN afin qu'il fonctionne de la même façon que les systèmes de stockage Cloud actuels.
Catalog : l'entreprise américaine qui a encodé Wikipedia dans l'ADN

L'entreprise américaine Catalog, spinoff du MIT, développe elle aussi un système de stockage des informations numériques dans l'ADN. Début juillet 2019, la firme a annoncé avoir réussi à encoder la version anglophone de Wikipedia dans des molécules d'ADN artificiel.
Au total, 16 gigabytes de données ont été stockés. Pour parvenir à cette prouesse, Catalog a utilisé un » DNA data writer » fonctionnant d'une façon similaire à une imprimante. Cette technique se révèle plus rapide et moins coûteuse que les autres déjà existantes à l'heure actuelle.
Le stockage de données dans les métabolites, une alternative à l'ADN
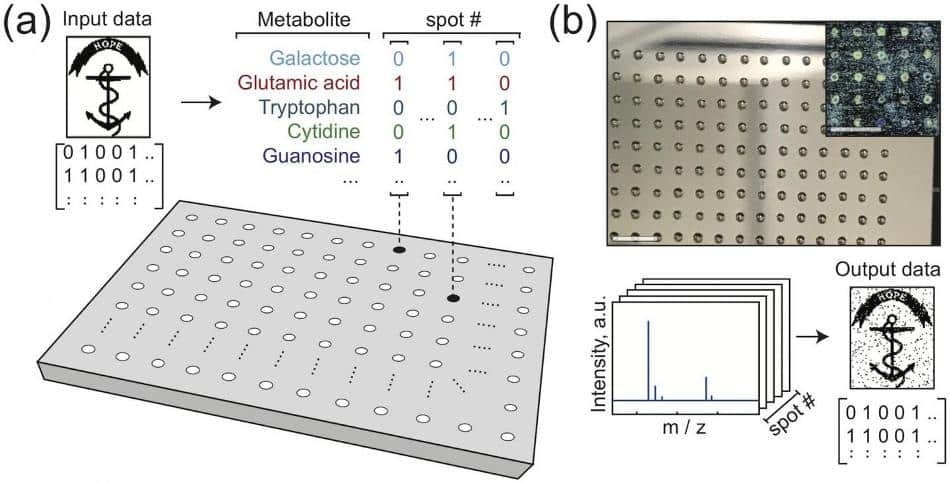
Les molécules de l'ADN ne sont pas les seules à pouvoir être utilisées pour le stockage de données. Début 2019, le chercheur Jacob Rosenstein de la Brown University de Rhode Island a voulu vérifier s'il était possible de stocker des données dans d'autres molécules.
À l'aide d'une équipe de chercheurs, il a créé des mixtures de métabolites : ces molécules servant à alimenter notre organisme. Les solutions liquides ainsi concoctées comportaient des sucres, des acides aminés et autres petites molécules utilisées par les organismes vivants pour différentes fonctions chimiques telles que la digestion.
Les données ont ensuite été encodées, en associant les valeurs binaires 1 et 0 à la présence ou à l'absence de métabolites. Les mixtures ont ensuite été disposées sur un plateau pour produire un certain nombre de points. L'absence ou la présence de métabolites spécifiques entre chaque point permet d'encoder l'équivalent en informations binaires d'images de plusieurs milliers de pixels.
Les chercheurs sont ainsi parvenus à encoder les images d'un chat égyptien, d'un bouquetin et d'une ancre. Ces images ont pu être décodées avec une précision de près de 99% grâce à un spectromètre.
Les métabolites présentent les mêmes avantages que l'ADN pour le stockage de données : stabilité, résistance aux conditions extrêmes, fonctionnement sans énergie… de plus, ces molécules étant plus petites et plus variées que celles de l'ADN, il est possible d'y stocker les données avec une densité encore supérieure. Elles pourraient donc représenter une alternative encore plus intéressante au stockage électronique…
Néanmoins, que ce soit pour le stockage de données dans l'ADN ou dans les métabolites, il faudra sans doute attendre encore quelques années pour que les premiers supports de stockage reposant sur cette technologie nouvelle soient commercialisés. À terme, il est toutefois probable que les molécules deviennent le principal support de stockage de données…
Quelques exemples de cas d'usage et d'expériences à succès
Alors qu'elle relevait encore de la science-fiction il y a seulement quelques années, la technologie de stockage ADN est désormais réalité. Voici quelques exemples d'expériences menées avec succès.
En octobre 2020, le généticien George Church de la Harvard Medical School de Boston et son équipe sont parvenus à encoder un extrait de musique du jeu vidéo Super Mario Bros dans les transitions entre l'exécution de bases génétiques synthétiques identiques. Elles ont ensuite été restaurées et jouées sur un ordinateur.
De son côté, Olgica Milenkoiv de l'Université de l'Illinois et son équipe ont développé une stratégie de carte perforée permettant d'encoder les données dans des entailles faites dans la colonne vertébrale de l'ADN. Cette technique a permis de stocker une copie de l'adresse de l'ancien président américain Abraham Lincoln à Gettysburg et une image du Lincoln Memorial.
À Zurich, à l'Institut Fédéral Suisse de Technologie, Robert Grass et son équipe ont mis en place une stratégie permettant l'intégration d'informations sur un objet à l'objet lui-même sous forme d'ADN. Par exemple, les instructions pour imprimer un objet en 3D peuvent être intégrées à l'objet lui-même. Cette approche a été nommée » DNA-of-things » ou ADN des Objets en référence à l'Internet des Objets.

L'ADN synthétique, plus solide que l'ADN naturel
En mars 2021, une équipe de chercheurs de l'Université de Californie a développé une méthode permettant de stocker les données sur des brins d'ADN synthétiques. Ces derniers présentent l'avantage d'être plus solides que l'ADN naturel.
En effet, l'un des plus gros points faibles de l'ADN est son manque de robustesse. Il peut être endommagé par la lumière du soleil, par les radiations, par la chaleur, par les enzymes ou par des réactions chimiques générales.
Par le passé, d'autres chercheurs ont envisagé de protéger les données encodées dans l'ADN par différentes méthodes. Il s'agirait par exemple d'abriter les molécules dans du verre à de faibles températures. Toutefois, l'équipe de l'UCI cherche à améliorer la molécule en elle-même grâce à l'ingénierie.
Pour y parvenir, les chercheurs ont utilisé une forme d'ADN synthétique : l'Acide Nucléique à Thréose (ANT). Ce polymère génétique artificiel a les mêmes composants de séquençage génétique que l'ADN naturel : adénine, thymine, cytosine et guanine.
Il peut même être appairé avec les chaînes ADN et ARN. Toutefois, le sucre ribose formant la colonne vertébrale d'une molécule d'ADN est remplacé par le sucre thréose. C'est ce qui protège l'ANT contre des menaces comme la digestion par nucléase : un processus de décomposition de l'ADN.
Afin de démontrer leur théorie, les chercheurs ont retranscrit la déclaration d'indépendance américaine et le sceau de l'Université de Californie dans l'ANT. Ils sont ensuite parvenus à restaurer les données en lisant le code chimiquement et en le convertissant de nouveau en données binaires.

Industrie du stockage ADN : un taux de croissance de 70,6% jusqu'en 2026
Le marché du stockage de données dans l'ADN pourrait connaître un taux de croissance impressionnant au fil des années à venir. C'est ce que révèle le rapport DNA Digital Data Storage Market publié par Research Insights en mars 2021.
Selon cette étude, le marché mondial du stockage de données dans l'ADN connaîtrait un taux de croissance de 70,6% par an au fil des cinq prochaines années. En 2026, ce marché pourrait valoir plusieurs milliards de dollars.
Les États-Unis investissent 50 millions de dollars
Comme l'informatique quantique ou l'intelligence artificielle, le stockage de données dans l'ADN se présente comme une technologie cruciale pour les années à venir. Afin de se placer en pionniers, les États-Unis investissent massivement dans ce domaine.
En janvier 2020, la IARPA (Intelligence Advanced Research Projects Activity) a lancé le programme Molecular Information Storage (MIST). Ce programme de recherche a pour but de créer un vaste système de stockage ADN.
Plusieurs équipes de chercheurs contribueront, sous la houlette du Georgia Tech Research Institute, du Broad Institute of MIT, de la Harvard University, du Los Alamos National Laboratory, du Sandia National Laboratories et du U.S. Army Research Laboratory.
Plusieurs entreprises privées participeront également à ces projets, dont Microsoft, Twist Bioscience et Roswell Biotechnologies. L'entreprise française DNA Script compte aussi parmi ces partenaires privés avec sa technologie de synthèse de données enzymatique.

DNA Script : l'entreprise française du stockage ADN
L'entreprise DNA Script est à ce jour le principal acteur français dans le domaine du stockage de données ADN. Son approche enzymatique de la synthèse ADN présente de nombreux avantages. Elle est plus rapide que les méthodes prédominantes basées sur la chimie.
Ainsi, DNA Script va participer à un projet financé par la IARPA dans le cadre du programme MIST, aux côtés du Molecular Encoding Consortium du Broad Institute, de l'université d'Harvard et de l'entreprise Illumina. Ce projet profite d'un budget de 20,7 millions d'euros.
Ensemble, ils ont pour mission de développer un prototype d'instrument capable de stocker et de restaurer un terabyte de données en seulement 24 heures. Ce système sera basé sur l'acide nucléique, et devrait permettre de réduire les coûts, l'empreinte carbone et la consommation énergétique du stockage de données.

DNA Data Storage Alliance : une coalition dédiée au stockage ADN
En novembre 2020, plusieurs entreprises dont Microsoft, Twist Bioscience, Illumina, Catalog, DNA Script et Western Digital ont formé la DNA Data Storage Alliance (DDSA). Cette coalition industrielle se fixe pour objectif » d'organiser l'industrie et de penser comment construire l'écosystème complet du stockage de données ADN « .
Alors que cette technologie est sortie du champ théorique pour se concrétiser, il est en effet nécessaire d'organiser son développement. L'objectif est aussi d'imaginer de nouveaux cas d'usage sortant de l'ordinaire…
- Partager l'article :


