
Le Data Mining est une composante essentielle des technologies Big Data et des techniques d'analyse de données volumineuses. Il s'agit là de la source des Big Data Analytics, des analyses prédictives et de l'exploitation des données. Découvrez la définition complète du terme Data Mining.
Data mining définition
Forage de données, explorations de données ou fouilles de données, ce sont les traductions possibles du data mining en Français. En règle générale, le terme Data Mining désigne l'analyse de données depuis différentes perspectives et le fait de transformer ces données en informations utiles, en établissant des relations entre les données ou en repérant des patterns. Ces informations peuvent ensuite être utilisées par les entreprises pour augmenter un chiffre d'affaires ou pour réduire des coûts. Elles peuvent également servir à mieux comprendre une clientèle afin d'établir de meilleures stratégies marketing.
Qu'est ce qu'un data mining ?
Les logiciels Data Mining font partie des outils analytiques utilisés pour l'analyse de données. Ils permettent aux utilisateurs d'analyser des données sous différents angles, de les catégoriser, et de résumer les relations identifiées. Techniquement, le Data Mining est le procédé permettant de trouver des corrélations ou des patterns entre de nombreuses bases de données relationnelles.
Le Data Mining repose sur des algorithmes complexes et sophistiqués permettant de segmenter les données et d'évaluer les probabilités futures. Le Data Mining est également surnommé Knowledge Discovery in Data (Data mining traduction ? La découverte de savoir dans les données).
Une évolution technologique naturelle

Le terme Data Mining est relativement récent, mais la technologie ne l'est pas. Depuis des années, les entreprises utilisent de puissants ordinateurs pour traiter les larges volumes de données accumulés par les scanners des supermarchés et pour analyser les rapports de recherches sur les marchés. De même, les innovations continuelles dans les domaines du calcul informatique, du stockage, et des logiciels statistiques augmentent fortement la précision des analyses et dirigent la réduction des coûts.
Données, informations et savoir dans le Data Mining
Données
Les données sont des faits, des nombres, ou des textes pouvant être traités par un ordinateur. Aujourd'hui, les entreprises accumulent de vastes quantités de données sous différents formats, dans différentes quantités de données. Parmi ces données, on distingue :
- Les données opérationnelles ou transactionnelles telles que les données de ventes, de coûts, d'inventaire, de tickets de caisse ou de comptabilité.
- Les données non opérationnelles, telles que les ventes industrielles, les données prévisionnelles, les données macro-économiques.
- Les métadonnées, à savoir les données concernant les données elles-mêmes, telles que les définitions d'un dictionnaire de données.
Informations
Les patterns, associations et relations entre toutes ces données permettent d'obtenir des informations. Par exemple, l'analyse des données de transaction d'un point de vente permet de recueillir des informations sur les produits qui se vendent, et à quel moment ont lieu ces ventes.
Savoir
Les informations peuvent être converties en savoir à propos de patterns historiques ou des tendances futures. Par exemple, l'information sur les ventes au détail d'un supermarché peut être analysée dans le cadre d'efforts promotionnels, pour acquérir un savoir au sujet des comportements d'acheteurs. Ainsi, un producteur ou un retailer peut déterminer quels produits doivent faire l'objet d'une promotion à l'aide du Data Mining.
Qu'est ce que un Data Warehouse ?
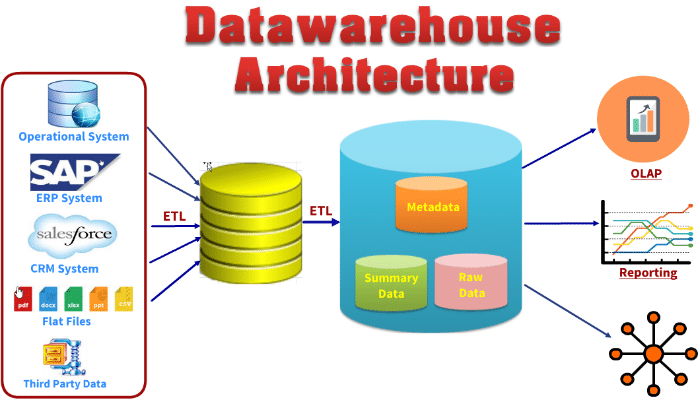
Les importantes avancées en termes de collecte de données, de puissance de calcul, de transmission de données, et de capacités de stockage permettent aux entreprises d'intégrer bases de données au sein de Data Warehouses. Le Data Warehousing est le procédé de centraliser la gestion et la recherche de données.
Grâce à une Data Warehouse, les entreprises peuvent diviser les données en segments d'utilisateurs précis, afin de les analyser en détail. Les analystes peuvent également commencer par le type de données qu'ils souhaitent utiliser puis créer une warehouse à partir de ces données.
Tout comme le Data Mining, le terme de Data Warehousing est relativement nouveau, tandis que le concept en lui-même existe depuis des années. Le Data Warehousing représente une vision idéale d'un répertoire central de données maintenu en permanence. Cette centralisation est nécessaire pour maximiser l'accès des utilisateurs et l'analyse.
Grâce aux grandes avancées technologiques, cette vision utopique est devenue une réalité pour beaucoup d'entreprises. De même, les avancées dans le domaine des logiciels analytiques permettent aux utilisateurs d'accéder librement aux données. C'est sur ces logiciels analytiques que repose le Data Mining.
Les méthodes de Data Mining

On dénombre cinq variétés du Data Mining :
- Association – chercher des patterns au sein desquelles un événement est lié à un autre événement.
- Analyse de séquence – chercher des patterns au sein desquelles un événement mène à un autre événement plus tardif.
- Classification – chercher de nouvelles patterns, quitte à changer la façon dont les données sont organisées.
- Clustering – trouver et documenter visuellement des groupes de faits précédemment inconnus.
- Prédiction – découvrir des patterns de données pouvant mener à des prédictions raisonnables sur le futur. Ce type de data mining est aussi connu sous le nom d'analyse prédictive.
À quoi sert le Data Mining dans le marketing ?
Le Data Mining est actuellement principalement utilisé par les entreprises focalisées sur les consommateurs, dans les secteurs du retail, de la finance, de la communication, ou du data mining marketing. Les techniques de Data Mining sont également utilisées dans différents secteurs de recherche, tels que les mathématiques, la cybernétique ou la génétique. Le Web Mining, utilisé dans le domaine de la gestion de relation client, vise à identifier des patterns de comportement des utilisateurs au sein des vastes quantités de données rassemblées par un site web.

Grâce au Data Mining, les entreprises peuvent déterminer les relations entre les facteurs internes tels que les prix, le positionnement d'un produit, les compétences des employés et les facteurs externes comme les indicateurs économiques, la concurrence, ou les informations démographiques sur les consommateurs.
Elles peuvent ensuite déterminer l'impact de ces relations sur les ventes, la satisfaction des consommateurs, et les bénéfices de l'entreprise. Enfin, ces relations peuvent être converties en informations pour obtenir des détails sur les données transactionnelles.
Avec le Data Mining, un retailer peut utiliser les enregistrements des achats de clients en point de vente pour envoyer des promotions ciblées basées sur l'historique d'achat d'un individu. En minant les données démographiques sur les commentaires des cartes de garantie, le vendeur peut développer des produits et des promotions pour attirer certains segments de consommateurs.
Exemples concrets de l'utilisation du Data Mining
À titre d'exemple, une chaîne d'épiceries du Midwest s'est servie des logiciels de Data Mining d'Oracle pour analyser les modèles d'achats locaux. L'enseigne à découvert que, lorsque les hommes achètent des couches le jeudi et le samedi, ils ont également tendance à s'acheter des bières. Une analyse approfondie a également démontré que ces clients font habituellement leurs courses hebdomadaires le samedi. Le jeudi, ils se contentent d'acheter quelques articles seulement. La chaîne en a conclu que les clients achètent leurs bières pour qu'elles soient prêtes pour le weekend.

Cette nouvelle information découverte a pu être utilisée de différentes façons pour augmenter le chiffre d'affaires. Par exemple, le rayon bière a été déplacé plus près du rayon couches. De même, le retailer s'est assuré que les bières et les couches ne seraient plus soldées le jeudi.
Suggestions de produits
Par exemple, Blockbuster Entertainment mine sa base de données historique de location de vidéos pour recommander des films à des clients individuels. De même, American Express peut suggérer des produits à ses clients en se basant sur leurs dépenses mensuelles.
Relations fournisseurs

Le géant WalMart se place en précurseur du Data Mining massif pour transformer ses relations avec les fournisseurs. WalMart collecte des données transactionnelles depuis 2900 boutiques dans 6 pays différents, et transmet ces données en continu vers sa Data Warehouse 7,5 terabyte fournie par Teradata. Plus de 3500 fournisseurs de WalMart peuvent accéder aux données relatives à leurs produits et effectuer des analyses de données. Ces fournisseurs utilisent les données pour identifier les patterns d'achat des clients à l'échelle du magasin. Ils utilisent l'information pour gérer les inventaires des magasins locaux et identifier de nouvelles opportunités. En 1995, les ordinateurs de WalMart ont traité près d'un million de requêtes de données complexes.
Analyse d'images
La National Basketball Association (NBA) explore une utilisation du Data Mining pouvant être utilisé en conjonction avec l'enregistrement d'images en provenance de matchs de basket. Le logiciel Advanced Scout permet d'analyser les mouvements des joueurs, pour aider leurs coaches à orchestrer des stratégies. Par exemple, une analyse du match entre les New York Knicks et les Cleveland Cavaliers le 6 janvier 1995 révèle que John Williams a marqué quatre paniers quand Mark Price était en défense. Cette pattern a pu être décelée par Advanced Scout, au même titre que la différence avec le pourcentage de précision moyen des Cavaliers pendant le match, élevé à 49,30%. En utilisant l'horloge universelle de la NBA, un coach peut automatiquement visionner les clips vidéo de chaque tir effectué par Williams quand Price était en défense, sans avoir à visionner des heures de capture vidéo.

Permettre aux consommateurs de contrôler leur empreinte numérique
À l'ère du numérique, des réseaux sociaux et du tout connecté, les marketers collectent en permanence et en temps réel des quantités massives de données. Les entreprises surveillent ce que les consommateurs postent, aiment, partagent sur les réseaux sociaux, les appareils qu'ils utilisent, les cartes de crédit avec lesquelles ils dépensent, les villes où ils sont situés. Pour cause, ces données permettent de promouvoir et de vendre des produits de façon personnalisée.
Désormais, de nombreuses firmes développent leur propre cloud marketing pour collecter des informations sur leur clientèle cible. Par conséquent, les entreprises et les gouvernements peuvent aisément utiliser les données personnelles pour leur business sans demander le consentement des usagers.
Afin de remédier à ce problème, et de permettre aux consommateurs de contrôler leurs données, la startup Digi.me a été fondée en 2009. Cette startup fournit aux consommateurs des outils leur permettant de se réapproprier leur empreinte numérique, de collecter et de partager des informations directement avec les entreprises selon leurs propres conditions. Digi.me se place en leader de l' « Internet of Me». Une fois que les utilisateurs prennent le contrôle de leurs données, elles ont la capacité d'en déterminer le prix et de dresser des barrières pour empêcher quiconque d'y accéder sans permission. Sans contrôle sur leurs données personnelles, les consommateurs sont tout bonnement exploités sans le savoir.
La technologie développée par Digi.me permet aux utilisateurs de télécharger leurs données et de les stocker sur internet. Les données sont nativement stockées sur un appareil individuel, et empêcher les tiers d'y accéder. La startup a levé 10,6 millions, dont 7 millions en 2016. Elle est également partenaire de Toshiba et Lenovo, et collabore avec les leaders des secteurs de l'assurance santé, de la finance et de l'industrie pharmaceutique.
Empêcher l'évasion fiscale avec le Data Mining

En Inde, le gouvernement est décidé à utiliser le data mining pour empêcher l'évasion fiscale. En effet, l'Inde est profondément affectée par ce fléau. Pour y remédier, le département des taxes va utiliser la technologie pour faciliter le paiement des taxes pour les citoyens honnêtes, et pour compliquer la tâche aux malhonnêtes. On ignore pour l'instant de quelle façon le data mining sera utilisé, mais davantage de détails devraient être dévoilés dans les mois à venir.
Recruter les meilleurs employés

Les professionnels du recrutement utilisent de plus en plus les outils de data mining pour localiser et identifier les employés les plus intéressants pour leur entreprise. En Irlande par exemple, les entreprises collectent les données en ligne sur les candidats pour dénicher les meilleurs talents. Les données permettent par exemple de déterminer le niveau de productivité et de satisfaction d'un candidat. C'est la raison pour laquelle LinkedIn a choisi de construire un nouveau building pour étendre son hub Irlandais, faisant office de QG européen. 200 nouveaux employés ont été ajoutés à une équipe rassemblant déjà 1000 personnes.
Comment fonctionne le Data Mining ?
Les technologies informatiques ont évolué de manière à ce que les systèmes transactionnels et les systèmes analytiques soient séparés. Le Data Mining assure la jonction entre les deux. Les logiciels de Data Mining analysent les relations et les patterns des données de transactions stockées en se basant sur des requêtes d'utilisateurs. Plusieurs types de logiciels analytiques sont disponibles : statistiques, Machine Learning, et réseaux neuronaux. En général, on dénombre quatre types de relations :
- Classes: Les données stockées sont utilisées pour localiser les données en groupes prédéterminés. Par exemple, une chaîne de restaurant peut miner les données d'achat des clients pour déterminer quand ont lieu les visites des clients et quelles sont leurs commandes habituelles. Cette information peut être utilisée pour augmenter le trafic en proposant des menus quotidiens.
- Clusters: Les données sont regroupées par rapport à des relations logiques ou aux préférences des clients. Par exemple, les données peuvent être minées pour identifier des segments de marché ou des affinités de clients.
- Associations: Les données peuvent être minées pour identifier des associations. L'exemple des couches et des bières cité plus haut est un exemple de minage associatif.
- Patterns séquentielles: Les données sont minées pour anticiper les patterns de comportements et les tendances. Par exemple, un vendeur d'équipement extérieur peut prédire les probabilités qu'un sac à dos soit acheté en se basant sur les achats de sac de couchage et de chaussures de randonnée d'un client.

Le Data Mining repose sur cinq éléments majeurs :
- L'extraction, la transformation, et le chargement de données transactionnelles sur le système de Data Warehouse.
- Le stockage et la gestion de données dans un système de base de données multidimensionnel.
- Fournir l'accès aux données aux analystes de business et aux professionnels des technologies informatiques.
- Analyser les données grâce à un logiciel applicatif.
- Présenter les données sous un format utile, comme un graphique ou un tableau.
Différents niveaux d'analyse sont disponibles :
- Les réseaux de neurones artificiels: Des modèles prédictifs non linéaires qui apprennent par l'entraînement et s'apparentent à des réseaux neuronaux biologiques dans leur structure.
- Algorithmes génétiques: Les techniques d'optimisation utilisent des procédés tels que la combinaison génétique, la mutation, et la sélection naturelle dans un design basé sur les concepts de l'évolution naturelle.
- Les arbres décisionnels: Ces structures en forme d'arbres représentent des ensembles de décisions. Ces décisions génèrent des règles pour la classification d'un ensemble de données. Les méthodes spécifiques d'arbres décisionnels incluent les Arbres de Classification et Régression (CART), et les Chi Square Automatic Interaction Detection (CHAID). Ces deux méthodes sont utilisées pour la classification d'un ensemble de données. Elles fournissent un ensemble de règles pouvant être appliqués à un nouvel ensemble de données pour prédire quels enregistrements auront un résultat. Le CART segmente un ensemble de données en créant une division à deux issues, tandis que le CHAID segmente l'ensemble en utilisant des tests de chi square pour créer des issues à plusieurs voies. En général, CART requiert moins de préparation de données que CHAID.
- La méthode du voisin le plus proche: Cette technique classifie chaque enregistrement d'un ensemble de données en se basant sur une combinaison des classes du k, similaire à un ensemble de données historique.
- L'induction de règle: L'extraction de règles « si-alors » depuis les données, basées sur des signifiances statistiques.
- Data visualization: L'interprétation visuelle de relations complexes dans les données multidimensionnelles. Les outils graphiques sont utilisés pour illustrer les relations de données.
Le Data Mining Process en 5 étapes
Le processus de Data Mining se décompose en 5 étapes. En premier lieu, les entreprises collectent les données et les chargent dans les Data Warehouses. Par la suite, elles stockent et gèrent les données, sur des serveurs physiques ou sur le Cloud. Les Business analysts, les équipes de management et les professionnels de l'informatique accèdent à ces données et déterminent comment ils souhaitent les organiser. Puis, le logiciel applicatif permet de trier les données en se basant sur les résultats utilisateurs. Enfin, l'utilisateur final présente les données sous un format facile à partager comme un graphique ou un tableau.
Les 3 propriétés principales du Data Mining
On dénombre 3 propriétés principales du Data Mining Big Data :
- La découverte automatique de patterns
Le Data Mining repose sur le développement de modèles. Un modèle utilise un algorithme pour agir sur un ensemble de données. La notion de découverte automatique se réfère à l'exécution de modèles de Data Mining. Les modèles de Data Mining peuvent être utilisés pour miner les données sur lesquelles ils sont bâtis, mais la plupart des types de modèles peuvent être généralisés à de nouvelles données. Le processus permettant d'appliquer un modèle à de nouvelles données est appelé scoring.
- La prédiction de résultats probables
De nombreuses formes de Data Mining sont prédictives. Par exemple, un modèle peut prédire un résultat basé sur l'éducation et d'autres facteurs démographiques. Les prédictions ont une probabilité associée. Certaines formes de Data Mining prédictif génèrent des règles, qui sont les conditions pour obtenir un résultat. Par exemple, une règle peut spécifier qu'une personne dotée d'un bachelor et vivant dans un quartier précis a une probabilité d'avoir un meilleur salaire que la moyenne régionale.
- La création d'informations exploitables
Le Data Mining permet de dégager des informations exploitables de larges volumes de données. Par exemple, un planificateur urbain peut utiliser un modèle pour prédire le revenu en se basant sur les données démographiques pour développer un plan pour les ménages à bas revenu. Une agence de location de voiture peut utiliser un modèle pour identifier des segments de consommateurs afin de créer une promotion ciblant les clients à forte valeur.
Quelle infrastructure technologique est requise ?

Aujourd'hui, les applications de Data Mining sont disponibles dans toutes les tailles pour mainframe, serveur ou PC. Les prix des systèmes sont compris entre plusieurs milliers de dollars pour les plus petites applications et jusqu'à 1 million de dollars par terabyte pour les plus larges. Les applications d'entreprises sont généralement comprises entre 10 gigabytes et plus de 11 terabytes. NCR a la capacité de délivrer des applications de plus de 100 terabytes. Il existe deux principaux facteurs technologiques :
- La taille de la base de données: Plus le nombre de données à traiter et à maintenir est important, plus un système puissant est requis.
- La complexité des requêtes: Plus les requêtes sont complexes et nombreuses, plus un système puissant est requis.
Le stockage de bases de données relationnelles et les technologies de gestion sont adéquats pour beaucoup d'applications de data mining inférieures à 50 gigabytes. Cependant, cette infrastructure doit être largement augmentée pour prendre en charge des applications plus importantes. Certains vendeurs ont ajouté des capacités d'indexage plus importantes pour augmenter les performances de requêtes. D'autres utilisent de nouvelles architectures matérielles telles que les Massiely Parallel Processors (MPP) pour améliorer le temps de traitement des requêtes. Par exemple, les systèmes MPP de NCR lient des centaines de processeurs Pentium pour atteindre des niveaux de performance supérieurs aux meilleurs superordinateurs.
Les logiciels Data Mining
Les logiciels de Data Mining analysent les relations entre les données et repèrent des patterns en fonction des requêtes des utilisateurs. Par exemple, un logiciel peut être utilisé pour créer des classes d'information. Par exemple, un restaurant peut utiliser le Data Mining pour déterminer à quel moment proposer certaines offres. Il faudra alors chercher dans les informations collectées, et créer des classes en se basant sur les moments auxquels ont lieu les visites de clients et ce qu'ils commandent.
Dans d'autres cas, les Data Miners trouvent des clusters d'informations en sa basant sur des relations logiques, ou bien ils cherchent des associations et des patterns séquentielles pour tirer des conclusions sur le comportement des utilisateurs. Pour tenter l'aventure, des logiciels de Data Mining existent. Orange, Weka, RapidMiner ou Tanagra sont quelques uns des outils open source disponibles sur le Web. Des licences professionnels pour le Data Mining 19 sont également disponibles. Parmi les plus célèbres d'entre elles, SPSS distribué par IBM, Entreprise Miner de SAS, ou encore Microsoft Analysis Services de la firme de Redmond.
Des cours de Data Mining
De nombreuses universités consacrés aux sciences informatiques et mathématiques explorent cette technique de probabilité. Les cours de Data mining et les moocs sont facilement disponibles sur le Web afin de comprendre et explorer plus en détails les possibilités de cette science associée au Big Data. Il y a de nombreux cours de Data Mining en PDF que vous pouvez télécharger. Attention, le niveau varie suivant le type d'enseignement. Pour notre part, nous vous recommandons les travaux de Stéphane Tufféry, Président du Comité Scientifique du CESP de l'université Rennes 1. Spécialisé dans ce domaine, il a même écrit un ouvrage à ce sujet.
Quels sont les inconvénients du data mining ?
Bien que le data mining ait facilité la collecte de données, il présente certains inconvénients, notamment en termes de coût. En fait, cette technique implique l'utilisation de nombreuses technologies pour le processus de collecte des données. Chaque donnée générée nécessite son propre espace de stockage ainsi que sa maintenance. Cela peut augmenter considérablement le coût de mise en œuvre. De plus, pour la sélection des outils et d'autres opérations, un spécialiste doit être engagé, ce qui peut également contribuer aux dépenses globales.
Le vol d'identité est un problème important lors de l'utilisation du data mining. Un manque de sécurité risque d'entraîner des failles dans la sécurité. Diverses informations sur les clients sont collectées dans l'exploration de données. Avec une telle quantité de données, les pirates pourraient facilement y accéder et voler des informations critiques.
Le data mining soulève de nombreux problèmes de confidentialité. Les informations recueillies pour l'exploration de données peuvent être utilisées à d'autres fins en dehors des objectifs visés. Certaines pourraient être divulguées sans le savoir ou être vendues à d'autres personnes en violant intentionnellement la vie privée des utilisateurs. Ceux qui sont en mesure d'acquérir ces données peuvent potentiellement suivre les individus.
Il existe différents outils de minage disponibles en fonction de leur mode de fonctionnement. Chacun d'entre eux peut avoir un algorithme et une conception différents. Sans une connaissance technique appropriée, la sélection de l'outil sera une tâche difficile. Par conséquent, un technicien qualifié doit être déployé pour le processus de sélection des outils.
- Partager l'article :



Bon jour,
je suis un chercheur, je travail sur la valorisation des boues et tous ce qui est eaux usées.
est ce que je pe intégré mon axe de recherche sur data mining
Merci beaucoup vraiment des informations top
Ce sont des publications intéressantes et riches. Cette publication m’a permis de comprendre le mode de fonctionnement et l’importance du Data Mining. Merci beaucoup